Вам не нужна Чистая архитектура. Скорее всего
January 18, 2025
Введение
Сейчас среди Java/Kotlin команд распространено применение Чистой (ака Гексагональной, ака Луковой - Clean, Hexagonal, Onion) архитектуры для разработки бакэндов прикладных приложений (да и Android-приложений тоже). Однако это семейство архитектур в контексте прикладной разработки зачастую не даёт никаких преимуществ, а только привносит лишние церемонии и тем самым замедляет её.
В этом посте я подробно разбираю, почему, на мой взгляд Чистая архитектура не является лучшим выбором по умолчанию для прикладных приложений, и кратко рассказываю об альтернативной архитектуре (спойлер: Промышленная функциональная архитектура), которую использую в качестве дефолтной последние 3 года и пока что доволен.
Но перед тем как перейти к Чистой архитектуре, сначала надо разобрать принцип инверсии зависимостей (Dependency Inversion Principle, DIP).
Принцип инверсии зависимостей
Определение
Принцип инверсии зависимостей — это один из принципов SOLID, самого известного набора принципов объектно-ориентированного дизайна, разработанного Робертом Мартином, так же известным как дядюшка или анкл Боб. Формулировка принципа звучит так:
- HIGH LEVEL MODULES SHOULD NOT DEPEND UPON LOW LEVEL MODULES. BOTH SHOULD DEPEND UPON ABSTRACTIONS.
- ABSTRACTIONS SHOULD NOT DEPEND UPON DETAILS. DETAILS SHOULD DEPEND UPON ABSTRACTIONS.
- МОДУЛИ ВЫСОКОГО УРОВНЯ НЕ ДОЛЖНЫ ЗАВИСЕТЬ ОТ МОДУЛЕЙ НИЗКОГО УРОВНЯ. И ТЕ И ДРУГИЕ ДОЛЖНЫ ЗАВИСЕТЬ ОТ АБСТРАКЦИЙ.
- АБСТРАКЦИИ НЕ ДОЛЖНЫ ЗАВИСЕТЬ ОТ ДЕТАЛЕЙ. ДЕТАЛИ ДОЛЖНЫ ЗАВИСЕТЬ ОТ АБСТРАКЦИЙ.
Признаки кода с «плохим дизайном»
В своей оригинальной статье о принципе инверсии зависимостей анкл Боб предлагает три признака кода с «плохим дизайном»:
A piece of software that fulfills its requirements and yet exhibits any or all of the following three traits has a bad design.
- It is hard to change because every change affects too many other parts of the system. (Rigidity)
- When you make a change, unexpected parts of the system break. (Fragility)
- It is hard to reuse in another application because it cannot be disentangled from the current application. (Immobility)
Часть программного обеспечения, которая соответствует требованиям и в то же время обладает любой или всеми из следующих трёх характеристик, имеет плохой дизайн.
- Её трудно изменить, потому что каждое изменение затрагивает слишком много других частей системы. (Жёсткость)
- Когда вы вносите изменения, ломаются неожиданные части системы. (Хрупкость)
- Её трудно повторно использовать в другом приложении, потому что её невозможно отделить от текущего приложения. (Неподвижность)
И если жёсткость и хрупкость в разработке прикладных приложений более чем актуальны, то к неподвижности возникают вопросы.
Как часто вам хотелось переиспользовать бизнес-логику в другом контексте (другом приложении)? Притом не какую-то универсальную, вроде аутентификации, загрузки файлов или отправки письма для сброса пароля, а какой-нибудь хардкор — тот же набивший уже оскомину перевод денег между счетами в банке? Да ещё и, забегая вперёд, сменив в новом контексте надёжный™ Oracle на хипстерскую™ MongoDB или Cassandra?
В моей двадцатилетней практике такого не было ни разу. Аутентификацию, хранение файлов и отправку емейлов — да, регулярно переиспользую. И то методом copy-and-paste (и ни разу об этом не пожалел).
А вот код доменно-специфичной бизнес-логики — ни единого раза.
Поэтому для этого поста давайте договоримся, что переиспользуемость бизнес-логики в разных приложениях в контексте прикладной разработки - это приятный бонус, но не более того, и он не стоит дополнительных усилий.
Меж тем анкл Боб опирается именно на переиспользование бизнес-логики в разных приложениях для того, чтобы обосновать DIP.
Пример кода с «плохим дизайном»
Для того, чтобы обосновать применение DIP, Мартин берёт такой код в качестве примера «плохого дизайна»:
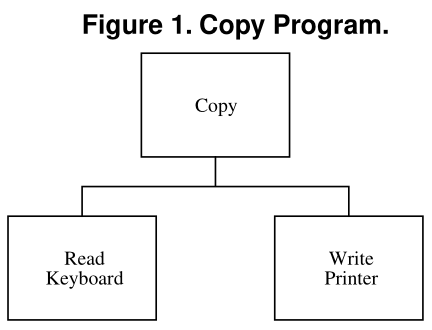
void Copy() {
int c;
while ((c = ReadKeyboard()) != EOF)
WritePrinter(c);
}И пинает его за то, что «бизнес-логика» (копирование символов) «неподвижна».
С тем, что эта «бизнес-логика неподвижна» - не поспоришь. Но подвижность, как мы договорились выше, для нас особой ценностью не является.
А что не так с «жёсткостью» и «хрупкостью» этого кода? Да на самом деле всё так и, чтобы притянуть за уши проблемы с ними, анкл Боб говорит:
For example, consider a new program that copies keyboard characters to a disk file. Certainly we would like to reuse the “Copy” module since it encapsulates the high level policy that we need. i.e. it knows how to copy characters from a source to a sink. Unfortunately, the “Copy” module is dependent upon the “Write Printer” module, and so cannot be reused in the new context.
Например, рассмотрим новую программу, которая копирует символы клавиатуры в файл на диске. Конечно, мы хотели бы повторно использовать модуль "Copy", поскольку он инкапсулирует необходимую нам политику высокого уровня. То есть он знает, как копировать символы из источника в приемник. К сожалению, модуль "Copy" зависит от модуля "WritePrinter" и поэтому не может быть повторно использован в новом контексте.
А для того чтобы всё-таки использовать модуль "Copy" в новой программе, он предлагает такой код:
enum OutputDevice {printer, disk};
void Copy(outputDevice dev) {
int c;
while ((c = ReadKeyboard()) != EOF)
if (dev == printer)
WritePrinter(c);
else
WriteDisk(c);
}И тут же говорит — это плохой код, который вносит новые зависимости в систему, и по мере развития системы и появления новых устройств в ней будет появляться всё больше зависимостей. И в итоге система станет жёсткой и хрупкой.
С этим тезисом снова спорить невозможно - это действительно плохой код, и если у вас бизнес-логика должна быть динамически настраиваемой на работу с разными механизмами, то ничего лучше DIP-а и полиморфизма я не знаю.
Однако моя практика показывает, что в современной разработке прикладных приложений бизнес-логика не переиспользуется и новых "устройств" появляться не будет. А, значит, новых зависимостей появляться не будет, система не станет жёсткой и хрупкой и DIP не нужен, ч.т.д.
И он не просто «не нужен», в контексте прикладной разработки DIP даже чуть-чуть вреден.
DIP не бесплатен
Далее, в качестве «Хорошего дизайна» анкл Боб предлагает следующий:
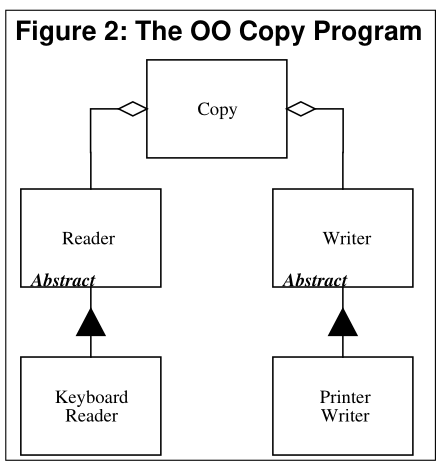
class Reader {
public:
virtual int Read() = 0;
};
class Writer {
public:
virtual void Write(char) = 0;
};
void Copy(Reader& r, Writer& w) {
int c;
while((c=r.Read()) != EOF)
w.Write(c);
}То есть, для того чтобы достичь подвижности, которая не имеет для нас ценности, мы должны добавить в проект два абстрактных класса.
Но эти абстрактные классы уже имеют свою цену - как минимум они увеличивают время сборки проекта и пересылки артефакта по сети при деплое. А ещё при навигации по проекту придётся делать два клика вместо одного. И в дереве файлов проекта на экране они будут занимать строчку. Наконец, в моей практике изменения в бизнес-логике очень часто требуют изменений в API механизма (добавить новый метод поиска в репозиторий, например) — и в случае следования DIP-у эти правки придётся вносить в двух местах, а не в одном.
Да, это всё копейки, но сто копеек — уже рупь. И платим мы его ни за что и можем не платить, не потеряв ничего. Или потеряв?
На порядок-другой реже, чем изменения в бизнес-логике, но смена механизмов в рамках одного приложения — переезд на новый механизм отправки почты или хранения файлов, например — всё же встречается при разработке прикладных приложений. Тут же без DIP-а уже никак не обойтись? Обойтись.
Проектирование API вместо кодирования интерфейсов
В своих иллюстрациях анкл Боб лукавит — почему-то в случае плохого дизайна у него в API механизмов фигурируют слова "Keyboard" и "Printer", а в случае хорошего дизайна — они чудесным образом исчезают.
Но никто же не мешает хорошему разработчику сделать так:
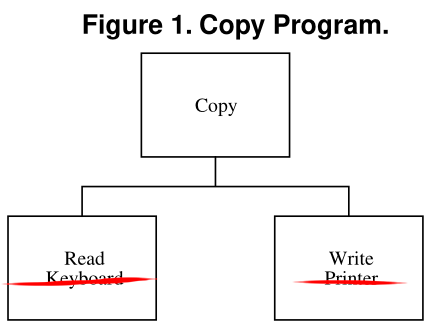
void Copy() {
int c;
while ((c = Read()) != EOF)
Write(c);
}И в этом случае, если в рамках одного приложения нам надо поменять механизм (перейти с печати на принтере на запись на диск), то эти изменения будут полностью инкапсулированы в процедуре Write.
В то же время никто не мешает плохому разработчику сделать так:
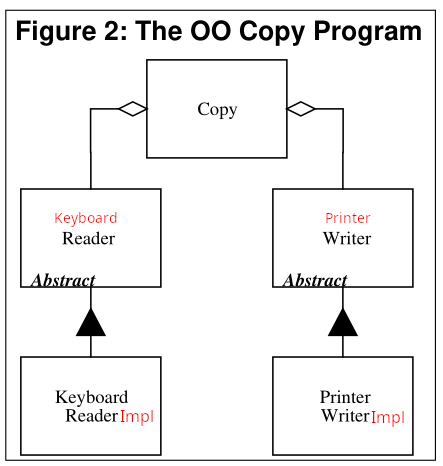
class KeyboardReader {
public:
virtual int Read() = 0;
};
class PrinterWriter {
public:
virtual void Write(char) = 0;
};
void Copy(KeyboardReader& r, PrinterWriter& w) {
int c;
while((c=r.Read()) != EOF)
w.Write(c);
}И тогда для перевода модуля "Copy" на работу с диском, его придётся "потрогать" хотя бы для того, чтобы ошибку в имени интерфейса исправить. А то и весь интерфейс придётся переделывать.
Притом не обязательно настолько грубо лажать. Достаточно лишь, например, в контракте репозитория "между строк пообещать", что он возвращает сущности, для которых автомагически выполняется ленивая загрузка и сохранение изменений (dirty checking). Или выставить в интерфейс механизма тип из библиотеки, используемой в её текущей реализации — условный Pageable из Spring.
И в этом случае DIP и интерфейс (абстрактный класс) между бизнес-логикой и репозиторием не спасут вас. Если вы захотите переехать с Oracle на Cassandra — вам придётся потрогать всю бизнес-логику, чтобы она научилась обходится без ленивой загрузки и дёти-чекинга. Вариант, что вы в контексте прикладной разработки сделаете полноценный ORM (OWCM - Object-wide-column-mapper?) поверх Cassandra, я исключаю как нереалистичный.
Выходит, для того, чтобы сделать код гибким, нам надо качественно проектировать API механизмов, а не кодировать дополнительный уровень косвенности в виде интерфейса или абстрактного класса.
Статическая работа с несколькими механизмами
Опытный читатель спросит: «А если я не могу одномоментно переключиться на новый механизм, и мне надо, чтобы в рантайме в зависимости от определённых условий использовался то старый, то новый?».
Да, такое бывает. Например, когда у вас есть какой-то огромный набор данных, дополняемый 24/7, который вы хотите перенести в новое хранилище. В этом случае у вас нет возможности одномоментно переключиться на новый механизм, как в предыдущем примере. И для того, чтобы обеспечить бесшовную миграцию, вам в течение какого-то периода придётся держать старое хранилище в режиме ридонли-бэкапа (искать данные сначала в новом хранилище и только если их там нет - идти в старое), а все записи делать в новое хранилище, пока не завершится процесс миграции данных.
Для большей конкретики, давайте рассмотрим такой код хранилища файлов:
class FilesStorage(private val jdbcTemplate: JdbcTemplate) {
fun saveFile(id: UUID, content: InputStream) {
jdbcTemplate.execute("INSERT INTO files ...")
}
fun getFile(id: UUID): InputStream? {
return jdbcTemplate.query("SELECT content FROM files ...")
.getBlob("content")
}
}И представим, что наш прототип стрельнул, нагрузка выросла, и мы решили перейти на хранение файлов в Minio.
Но даже в этом случае нам не нужен DIP и промежуточный интерфейс.
Для начала мы реализуем новый класс MinioFilesStorage, затем код из FilesStorage перенесём в новый класс JdbcFilesStorage, а сам FilesStorage перепишем так:
class FilesStorage(
private val jdbcFilesStorage: JdbcFilesStorage,
private val minioFilesStorage: MinioFilesStorage,
) {
fun saveFile(id: UUID, content: InputStream) {
minioFilesStorage.saveFile(id, content)
}
fun getFile(id: UUID): InputStream? {
return minioFilesStorage.getFile(id)
?: jdbcFilesStorage.getFile(id)
}
}И без единого изменения в коде бизнес-логики наш проект начинает работать с двумя механизмами одновременно.
Выходит, работать с несколькими механизмами одновременно мы можем и без лишних интерфейсов и DIP-а.
Конфигурируемая работа с нескольким механизмами
И тут на сцену должен выйти самый опытный читатель и сказать: «А вот я как-то делал коробочный продукт, который деплоился силами и на инфраструктуре клиентов, и к нам как-то пришёл жирный заказчик с чемоданом денег и сказал, что хочет использовать Cassandra вместо Postgres для хранения данных. И как тут выкрутится без DIP?».
Никак. Вот тут он вам наконец нужен.
Но, если API слоя персистанса спроектирован качественно (через него не текут детали реализации), то, в случае появления необходимости работы с несколькими хранилищами данных, внедрить DIP можно постфактум одним движением руки — рефакторингом "Extract Interface" в IDEA.
Да, этого движения можно было бы избежать, если сразу завести интерфейс, но:
- Вы бы платили всё это время копеечку за интерфейс;
- Клиент мог и не прийти;
- Это движение — капля в море, на фоне трудозатрат на повторную реализацию слоя персистанса.
И более того, как я писал в Проектирование API вместо кодирования интерфейсов DIP и интерфейсы сами по себе не спасли бы в этом случае.
Например, если API слоя персистанса — это интерфейсы Spring Data JPA репозиториев, и вся бизнес-логика полагается на ленивую загрузку и автоматическое сохранение изменений, то от жирного клиента и чемодана денег придётся отказаться. Потому что даже чемодана денег не хватит на то, чтобы переписать всё приложение.
И тут мы, наконец, приходим к Чистой архитектуре.
Чистая архитектура
Чистая архитектура, это, по сути, перенос принципа инверсии зависимостей на архитектурный уровень.
В одноимённой книге анкл Боб определяет Чистую архитектуру иллюстрацией:
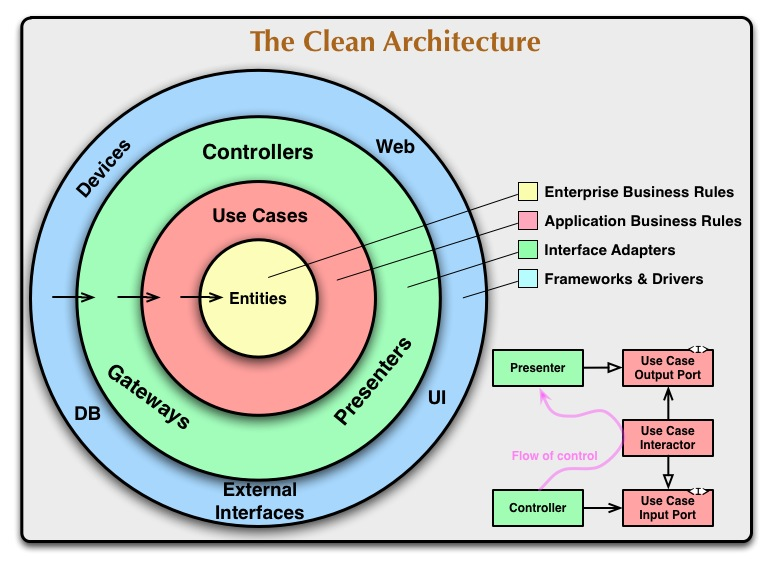
И «Правилом зависимостей»:
The overriding rule that makes this architecture work is the Dependency Rule: Source code dependencies must point only inward, toward higher-level policies.
Основным правилом, обеспечивающим работоспособность этой архитектуры, является правило зависимостей: Зависимости исходного кода должны указывать только внутрь, на политики более высокого уровня.
И, соответственно, она переносит на архитектурный уровень плюсы и минусы принципа инверсии зависимостей.
Чистая архитектура вводит в ваш проект «архитектурный налог» — как минимум вам придётся тратить время на создание, актуализацию, компиляцию и пересылку кода интерфейсов.
А, если вы решите реализовать Чистую архитектуру честно, и хотя бы в слоях сущностей и юзкейсов исключите зависимости от фреймворков, то «архитектурный налог» будет ещё выше. В этом случае помимо дополнительных интерфейсов, вам придётся ещё и написать модель фактически четыре раза: один раз в слое персистанса, один раз в слое бизнес-логики и по разу для маппинга туда и обратно (хотя условный Mapstruct сильно сократит код маппинга). А ещё надо будет завести собственные аналоги @Transactional, @EventListener, @Cachable и т. д. с их обработчиками, пускай и просто делегирующими вызовы в Spring.
И единственный случай, обусловленный требованиями, когда вы получаете что-то взамен, это если вы делаете продукт, который разворачивается на инфраструктуре клиентов, или платформу, которую клиенты дополняют собственным динамически загружаемым кодом (плагинами).
Также есть гуманитарный случай, когда Чистая архитектура может быть полезна: если у вас большая команда, с большой текучкой, непостоянным уровнем квалификации и перегруженным лидом. В этом случае честная реализация Чистой архитектуры с выделением слоёв сущностей и юзкейсов в отдельный(е) Gradle/Maven-модуль может помочь повысить качество дизайна API (но и это не гарантирует качественный дизайн).
Например, возвращаясь к примеру с поддержкой Cassandra, если бы бизнес-логика была в отдельном модуле, у которого в зависимостях нет ни JPA, ни Spring Data, то для того, чтобы предоставить контракт с ленивой загрузкой и автоматическим сохранением изменений — их пришлось бы реализовать самостоятельно. И вряд ли команда бы это сделала, соответственно в контракт они бы не утекли, добавить поддержку Cassandra было бы возможно и удалось бы заполучить жирного клиента и чемодан денег. Профит.
Таким образом, мы приходим к тому, что Чистая архитектура полезна только в двух случаях:
- Вы пишите платформу, которая с самого начала должна быть расширяемой;
- У вас слабая команда и вы пишете коробочный продукт, в котором высокая вероятность появления динамически конфигурируемых механизмов.
Однако к Чистой архитектуре вы пришли не от хорошей жизни, скорее всего. Скорее всего, у вас уже есть печальный опыт работы со слоёной архитектурой, которая быстро превратилась в большой ком грязи и стала жёсткой и хрупкой. По крайней мере именно так было в моём случае.
В своё время я не столько пришёл к Чистой архитектуре, сколько ушёл от классической слоёнки. И сделал пару небольших проектов с честной реализацией Чистой архитектуры — в слое домена (у меня юзкейсы и сущности были в одном Gradle-модуле) у меня был даже собственный интерфейс для транзакций.
Но сделав их, я офигел от "архитектурного налога". И перешёл на один из вариантов Функциональной архитектуры.
Функциональная архитектура
Определение
В отличие от Чистой, у Функциональной архитектуры нет единого авторитетного источника. Но в целом, можно охарактеризовать Функциональную архитектуру следующей иллюстрацией:
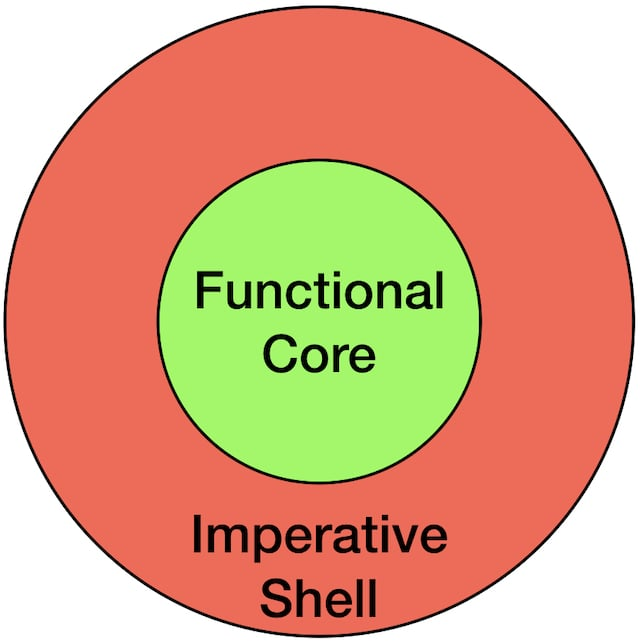
И несколькими правилами:
- Все зависимости должны быть направлены в сторону чистого ядра (Functional Core) — аналог правила зависимостей;
- Чистое ядро должно быть чистым в функциональном смысле - состоять из неизменяемых структур данных и чистых функций (функций, не выполняющих ввод-вывод, изменение данных и обращений к глобальному окружению);
- Максимум кода должен находиться в чистом ядре.
И если приглядеться (или прищуриться) — можно разглядеть много общего между Функциональной и Чистой архитектурами.
Чистое ядро может быть аналогом сущностей (Entities) в терминах Чистой архитектуры.
А императивная оболочка, в которую попадает весь ввод-вывод — это аналог адаптеров интерфейсов (Interface Adapters, но далее я буду использовать более распространённый термин — гейтвей) в терминах чистой архитектуры.
С аналогом юзкейсов же (у которого нет общепринятого названия, моя версия — оркестрация, можно ещё встретить варианты: workflow, операция алгебры) всё уже не так очевидно.
Есть хардкорные реализации Функциональной архитектуры на IO-монадах, в которых функции оркестрации являются чистыми. Концептуально он довольно сложен, поэтому в этом посте я его описывать не буду, а если интересно, то можно почитать в Functional and Reactive Domain Modeling, From Objects to Functions или Functional Design and Architecture, например. И, соответственно, я не представляю, как такой вариант затащить в свою практику коммерческой разработки — людей, которые могут или хотя бы хотят писать в таком стиле, не найдёшь днём с огнём.
Есть более приземлённый вариант реализации Функциональной архитектуры «по Влашину» без IO-монад, описанный в его книге Domain Modeling Made Functional и посте A primer on functional architecture.
В варианте Влашина за оркестрацию отвечают функции высшего порядка. Эти функции помещаются в чистое ядро, а функции для получения и сохранения данных передаются в них параметрами (перевод с марсианского: за оркестрацию отвечают методы классов сервисов приложения (юзкейсов), в которые гейтвеи внедряются через конструктор). Соответственно, чистота этих функций (методов) зависит от чистоты функций, которые были переданы в качестве параметров (гейтвеев).
И в таком исполнении Функциональная архитектура является строгим подмножеством Чистой архитектуры*, в котором на слои юзкейсов и сущностей наложено дополнительное ограничение в виде чистоты в функциональном смысле. А если учесть, что анкл Боб больше 10 лет программирует на Clojure и пишет посты с одами ФП и книги про функциональный дизайн, то вообще можно предположить, что Труъ Чистая архитектура по анкл Бобу и Функциональная архитектура по Влашину — это одно и то же.
Соответственно, в Функциональной архитектуре по Влашину вам точно так же придётся платить архитектурный налог, которого мы хотим избежать. Благо функциональная архитектура даёт нам такую возможность.
Промышленная функциональная архитектура
В отличие от Чистой архитектуры (по крайней мере в её общепринятой интерпретации), отказ от архитектурного налога в Функциональной архитектуре (в виде переноса оркестрации/юзкейсов в императивную оболочку и работы с гейтвеями напрямую) не возвращает вас к слоёнке и большему кому грязи. Оставшиеся дополнительные ограничения Функциональной архитектуры, помогать сохранить порядок в коде:
- Неизменяемая модель данных исключает появление циклов в зависимостях между агрегатами/сущностями;
- Исключение ввода-вывода из бизнес-логики, во-первых, в целом задаёт строгую верхнеуровневую структуру коду (оркестрация, ввод, вывод, бизнес-логика), и, во-вторых, уменьшает количество связей в графе зависимостей методов, за счёт того, что каждая ветка бизнес-логики не достаёт себе каждый кусочек нужных данных по отдельности.
Соответственно, при отказе от архитектурного налога в Функциональной архитектуре вы теряете только лишь подвижность юзкейсов и возможность динамической конфигурации гейтвеев. Что, напомню, не является универсальной ценностью в контексте разработки прикладных приложений.
Такой вариант Функциональной архитектуры я называю промышленным, потому что он, на мой взгляд, лучше ложится на реалии промышленной разработки, где используют преимущественно императивные по природе языки программирования, а большинство разработчиков не слышали и не хотят слышать про теорию категорий и каррирование (currying) функций (и я их прекрасно понимаю). А за попрание идеалов функционального программирования я оправдываюсь перед совестью тем, что «грязь» (ввод-вывод) — это то, ради чего мы пишем информационные системы. И как ни обкладывай её монадами и инверсией зависимостей — в продакшене ввод-вывод — это то, ради чего пользователи используют наши системы.
Если вы пока что не знакомы с идеями функционального программирования, и вам этот раздел показался тарабарщиной — прошу, не пугайтесь, все эти идеи прекрасно ложатся на почти привычный Java/Kotlin/Spring-код. У меня есть доклад на Joker '24 и пост с его расшифровкой, где я разбираю три примера рефакторинга реального коммерческого кода к Промышленной функциональной архитектуре, оставаясь, по большому счёту, в привычных большинству разработчиков рамках.
Здесь же я проиллюстрирую Промышленную функциональную архитектуру на анкл Бобовском примере с копированием байт.
Пример
И если переписать анкл Бобовский пример по Промышленной функциональной архитектуре, то… Ничего не поменяется.
В оригинальном примере нет бизнес-логики, которую можно было бы вынести в чистое ядро.
Поэтому давайте немного усложним его и добавим требование, что при копировании нам необходимо шифровать данные алгоритмом Цезаря.
В этом случае "плохой дизайн" выглядел бы так:
void Copy() {
int key = 3;
int c;
while ((c = Read()) != EOF) {
// Так как реализация шифра Цезаря тут исключительно в иллюстрационных целях,
// я сгенерировал её с помощью ИИ и толком не перепроверял, поэтому не ручаюсь за корректность
int charCode = c - 97;
charCode = (charCode + key) % 26;
Write(charCode + 97);
}
}И для того, чтобы привести этот пример к Промышленной функциональной архитектуре — нам надо вытащить «бизнес-логику» (алгоритм шифрования) в отдельную функцию:
void Copy() {
int key = 3;
int c;
while ((c = Read()) != EOF) {
Write(encrypt(key, c));
}
}
int encrypt(int key, int c) {
// Реализацию шифра цезаря сгенерял чат-ботом
int charCode = c - 97;
charCode = (charCode + key) % 26;
return charCode + 97;
}И теперь наша «бизнес-логика» стала вполне себе «подвижной» — её без проблем можно будет переиспользовать в другом контексте и не тащить при этом за собой интерфейсы и не приседать с адаптерами, затачивающими стандартную библиотеку под эти интерфейсы. Всё.
Заключение
У принципа инверсии зависимостей и Чистой архитектуры есть своя область применения — системы, в которых необходимо обеспечить динамическую конфигурацию «механизмов», и проекты, в которых надо держать неквалифицированных разработчиков в «ежовых рукавицах». Но есть и своя цена — разработка, поддержка, компиляция и пересылка дополнительных слоёв абстракции.
И так как в разработке прикладных приложений необходимость обеспечить динамическую конфигурацию «механизмов» возникает достаточно редко, использовать её как вариант по умолчанию для квалифицированных команд - нерационально, на мой взгляд.
В качестве альтернативы по умолчанию я предлагаю использовать Промышленную функциональную архитектуру, которая даёт «надёжный», «гибкий» и «подвижный» код бизнес-логики без лишних абстракций и церемоний.