Как я превратил легаси-проект в конфетку за полгода. Том 2
September 26, 2023
Введение
Это второй том эпопеи, о том как, я превратил легаси-систему в конфетку за полгода:
- Том первый. "Пациент скорее мёртв, чем жив" - описание проекта, история получения разрешения на реинжиниринг и планирование работ
- Том второй. "Доктор сказал в морг, значит в морг" - описание процесса работы, что пошло не по плану, как факапились в проде и чем всё закончилось
- Том третий. "Анатомический атлас конфетки" - детали реализации "конфетки"
- Том четвёртый. "Это наследственное" - какие проблемы были вызваны сменой архитектуры и стека, а также необходимостью параллельной работы со старым бэком
Первая часть закончилась на том, что я составил план, которого мне оставалось придерживаться. В этой части я расскажу о том, насколько мне это удалось.
Процесс работы команды
Глобально процесс работы мы организовали "по классике" - псевдоскрам с двухнедельными спринтами и дейликами.
Перед стартом каждого спринта я для каждого эндпоинта, запланированного на этот спринт, назначал ответственного за него разработчика. Процесс работы внутри спринта у нас менялся несколько раз и в итоге мы остановились на таком:
- Разработчик создаёт фича-ветку от мастера для каждого эндпоинта;
- Разработчик реализует эндпоинт и проходит ревью в ветке;
- Фича-ветка мёржится в мастер;
- Раз в спринт (седьмой день из десяти) объявляется код фриз;
- QA начинает тестировать релиз-кандидат на dev-стенде, мёржи новых эндпоинтов в мастер запрещены;
- На десятый день (или после того, как QA проверят все задачи, вошедшие в версию), на мастер вешается тег и он заливается на stage-стенд, там гоняются автоматические тесты QA-команды;
- Утром одиннадцатого дня спринта (или на следующий рабочий день, после заливки на стейдж) тег заливается на prod-стенд;
- Код фриз снимается, запускается очередной спринт/релизный цикл.
Единственным, что было у нас не как у всех [из тех команд, в которых я работал] - на дейликах мы рассказывали не кто чем занимался и будет заниматься, а выясняли кто что должен сделать для того, чтобы каждая задача в работе максимально быстро оказалась на проде. Сложно сказать, помог ли нам такой формат быстрее закончить реинжиниринг, но мне ближе фокус на достижении целей, а не максимизации утилизации ресурсов.
Отслеживание прогресса
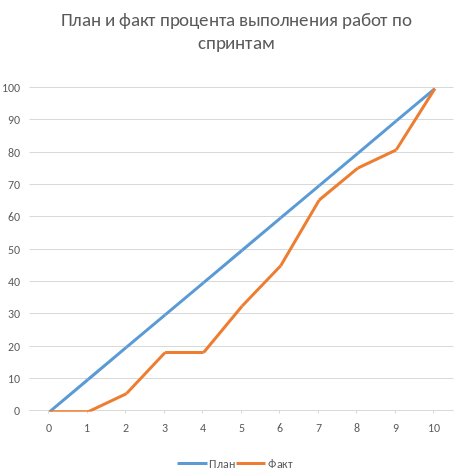
В конце каждого спринта я подбивал факт (какие эндпоинты были сделаны за спринт) и актуализировал план (перераспределял оставшиеся эндпоинты по оставшимся спринтам). В основном план менялся из-за того, что за спринт не успевали сделать то, что запланировали. Однако были и другие причины изменений:
- Бывало и перевыполнение плана;
- Удаление эндпоинтов из плана (в основном это были RPC-эндпоинты, которые теряли смысл после объединения баз данных аккаунтов с наблюдением и профиля с дневником);
- Помещение эндпоинтов в один спринт (после обнаружения в процессе работы их высокой сцепленности).
План и факт я вёл в таких табличках в Confluence:

Первые спринтов 6 я действовал по принципу всё или ничего - фича и трудозатраты не неё переносится в факт только полностью и после того, как она пройдёт QA и окажется stage-стенде.
Мотивацией такого подхода было то, что я боялся, что мы свалимся в имитацию бурной деятельности без видимых результатов для заказчика.
Однако из-за такого подхода у нас пару спринтов получилось 0 единиц сделанной работы и в целом видимая мощность команды сильно прыгала (как видно на скрине), из-за чего сложно было понять, попадаем ли мы в план. Поэтому после 6 спринта я перешёл на пропорциональный перенос работ в факт - на глаз определял процент выполнения задачи и соответствующий процент "майки" заносил в факт, уменьшая остаток в плане.
Как проходил деплой
С деплоем мы тоже ничего нового не выдумали и воспользовались стратегией Strangler Fig.
Завели новый сервис в k8s-кластере и начали в нём реализовывать эндопинты. По мере реализации эндпоинтов на уровне Ingress переводили запросы на новый бэк.
В целом эта стратегия хорошо сработала и ни разу не принесла нам существенных проблем. Возможно, в том числе и потому, что я старался минимизировать риски при определении порядка реинжиниринга эндпоинтов (подробно описано в первом томе).
Но пара небольших сложностей всё-таки возникла.
Один раз мы сломали dev-стенд из-за того, что перевели на новый бэк эндпоинт, путь которого был префиксом к ещё не реализованному эндпоинту. В результате мы примерно час потратили на чатики и выяснение кто виноват, а на корректную настройку роутинга у девопса ушло чуть больше обычных пяти минут.
Также мы несколько раз задерживали релиз готовых эндпоинтов (перевод трафика на них), так как на том же пути но с другими методами оставались ещё нереализованные эндпоинты. Тут девопс сказал, что в принципе это можно сделать, но надо изучать вопрос и мы решили, что релиз этих эндпоинтов может немного подождать.
Что пошло не по плану
Спринты
Первое, что пошло не по плану - скорость работы команды в первые два спринта. При оценке задач я ориентировался на среднюю скорость работы и не учёл несколько факторов, осложнявших старт:
- В новом проекте приходилось сетапать много "инфраструктурного" кода (например, запуск тестконтейнеров без поломки кэша Spring-контекстов), и решать нетиповые задачи, вызванные сменой архитектуры (например, настраивать работу с несколькими DataSource в Spring Data JDBC);
- Команда видела C# в первый раз в жизни, и для юниоров читать код (который фактически выступал в роли ТЗ) на незнакомом языке было довольно сложно;
- Команда не ориентировалась в кодовой базе оригинального проекта, так как не работала с ним до начала реинжиниринга;
- Приходилось искать решения нетипичных проблем из-за наследия .net-бэка (например, обработку CamelCase enum-ов в (де)сериализации DTO).
Из-за этого (плюс стратегия "всё или ничего" в учёте факта) за первые два спринта (или за 25% изначально запланированных спринтов) мы смогли сделать только 5% работы. Поэтому после второго спринта пришлось сказать, что это была "разминка" и вот теперь оставшиеся 95% работы мы точно сделаем за 8 спринтов. Благо у нас был запас по времени в 17 человеко/дней, так как при планировании спринтов, я настолько оптимистично набирал в них задачи, что затолкал работ на 177 дней в спринты на 160 дней (8 спринтов * 2 человека * 10 дней в спринте).
После этой коррекции в целом всё пошло более-менее по плану и в итоге мы уложились в 10 спринтов, единственное что в последнем спринте одному разработчику пришлось устроить 24 часовой хакатон (по собственной инициативе).
Вся эта драма хорошо видна на графике процента выполнения проекта:
Тестирование силами разработчиками
Как это должно было быть
Вообще, Эргономичный подход предполагает вполне конкретный план тестирования. Его полное описание пока не опубликовано, но суть его сводится к следующими принципам:
- Тестируется система в конфигурации, максимально приближённой к боевой. В частности, мокаются только внешние и дорогие или нестабильные зависимости (например, внешний сервис отправки почты), и мокаются они на уровне HTTP.
- Тесты взаимодействуют с системой через публичное API - в общем случае и сетап и действие и верификация выполняются через него. Работа через "кишочки" допустима, но каждый такой случай рассматривается отдельно и взвешивается ценность теста, его сцепленность с продовым кодом и потенциальные последствия этой сцепленности;
- Тесты пишутся исходя из сценариев использования - каждый юзкейс в ТЗ, должен быть покрыть тестом;
- Все задокументированные ошибки API должны быть покрыты тестами (тут, при необходимости, допускается использование моков);
- В бизнес-логике тестами должны быть покрыты все ветки. Если бизнес-логика развесистая, её допустимо тестировать в обход публичного API и напрямую вызывать функции ядра. Чтобы упростить тестирование бизнес-логики, она должна быть реализована в чистых функциях без ввода-вывода.
И в моей практике эти принципы работают очень хорошо - по статистике, в проектах, покрытых такими тестами, команда QA находит мажорные баги примерно раз в три месяца. Под мажорными я понимаю баги, которые могли бы затронуть большинство пользователей.
Но в Проекте Э пришлось отойти от этих принципов. И пожалеть об этом.
Как это было
Честно говоря, я уже не помню конкретных причин (дело было почти год назад), но я не стал в тестах поднимать контейнеры старого бэка. Скорее всего, я решил так сделать из-за того, что [быстро] не придумал как "натравить" старый бэк на БД в testconainers-ах.
И из-за того, что мы шли снаружи внутрь и начинали с методов чтения, у нас не было ручек для сетапа фикстуры тестов и верификации через публичное API. И в целом писать тесты на сценарии использования мы не могли, потому что они нам не достались от старой команды, а времени и денег на реинжиниринг ещё и их не было. Поэтому тестировать я планировал не сценарии использования, а отдельные эндпоинты.
Соответственно, новый план тестирования был такой:
- Сначала пишем тест на отдельный эндпоинт, который проходит на старом бэке, поднятом разработчиком руками;
- Переводим тест на вызов нового бэка;
- Выполняем реинжиниринг этого эндпоинта;
Но практически сразу в этом плане обнаружилась дыра - как сетапить фикстуру? Через публичное API нельзя, так как его не будет на новом бэке. А через БД нельзя, так как было непонятно, как натравить старый бэк на базу в testcontainers.
В итоге мы начали писать тесты сразу на эндпоинты в новом бэке и сетапить фикстуру SQL-скриптами. А RPC-вызовы к старому бэку мокали на уровне RabbitMQ.
Кроме того, из соображений минимизации сроков реинжиниринга, мы отказались от покрытия тестами негативных сценариев.
За все эти решения мы поплатились большим (84 штуки за 5.5 месяцев) количеством багов и хрупкостью тестов.
К чему это привело
Баги
Большинство багов было связано с нарушением обратной совместимости. Но были и баги в негативных сценариях, и баги вида "тесты на метод А проходят, тесты на метод Б проходят, а вот когда фронт зовёт метод А, а потом метод Б - всё взрывается".
Баги обратной совместимости мы в конце концов победили такой схемой:
- Перед стартом работ над эндпоинтом команда QA-пишет тест на структуры запроса и ответа в Postman;
- В мёрж реквест разработчик прикладывает два скриншота - как тест проходит с новым и старым бэком.
Но незадолго до введения этого правила я уволил стажёра (спойлер 😱), которая генерировала большинство багов обратной совместимости, поэтому сложно сказать, что внесло больший вклад - скрины в МРах или увольнение стажёра.
А ошибки в сценариях использования (как негативных, так и позитивных) мы сейчас постепенно изводим возвратом к принципам тестирования ЭП.
Хрупкость тестов
Также мы поплатились и за сетап БД SQL-скриптами.
Для моков старого бэка ответы генерировались из чёрт знает каких данных (текущего состояния БД на рабочей машине разработчика). Соответственно, когда мы эти методы переносили в новый бэк, то для написания скриптов сетапа фикстуры приходилось героически определять входные данные, которые должны быть поданы в операцию, чтобы получить заданный результат.
Второй проблемой, актуальной до сих пор, стала хрупкость тестов. Во время реинжиниринга она проявлялась в том, что при переносе на новый бэк внутреннего эндпоинта приходилось прописывать скрипты сетапа БД для него во все тесты, в рамках которых этот эндпоинт вызывался. А сейчас - при изменении схемы БД приходится править сетап фикстуры для множества тестов.
Первую проблему мы частично решили введением "эталонной БД" - взяли дамп с одного из стендов и для генерации мок-данных запускали бэк на нём.
А с хрупкостью тестов живём до сих пор и переводим их на публичное АПИ по мере появления проблем.
Тестирование силами команды QA
План тестирования командой QA сводился к паре фраз: "Тестировать будем на дев стенде и стейдже. На деве - через Постаман, на стейдже - через МП".
Но и в этом плане мы тоже быстро уткнулись в дыру - как тестировать эндпоинт?
На момент начала реинжиниринга бэк-команда видела проект в первый раз, а команды QA и мобильной разработки работали с ним четыре месяца. Поэтому ответить на вопрос "где этот эндпоинт используется?" с ходу не мог никто и определение сценариев, которые он мог затронуть, и тест кейсов, которыми его можно проверить, превращалось в целое расследование.
Эту проблему мы в полной мере так и не решили до самого конца проекта реинжиниринга - буду благодарен, если расскажете в комментариях хороший способ её решения.
Модель ветвления
Модель ветвления я не планировал - она сама собой как-то оказалась GitLab Flow-ом.
Изначально у нас было три постоянных ветки:
- re-integration (от reengeineering) - деплоится на дев стенд;
- develop - деплоится на стейдж;
- master - деплоится на прод;
Далее, общий процесс был теоретически должен был быть такой:
- Разработчики создают фича ветки от re-integration;
- Делают фичи и проходят ревью;
- Мёржат фича ветки в re-integration;
- Команда QA проверяет фичи через Postman на деве;
- Раз в спринт re-integration мёржится в develop;
- Команда QA проверяет работу МП на стейдже;
- После аппрува QA develop мёржится в master и деплоится в прод.
Баги чинятся в фича -ветке, отрезанной от постоянной ветки, соответствующей стенду, на котором баг был найден. После фикса фича ветки мёржатся в постоянную и бэкпортятся на более "ранние" ветки, при необходимости.
И из-за изрядной доли хаоса в процессах разработки и тестирования, особенно на ранних этапах, у нас были две проблемы:
- Довольно много багов находили уже на стейдже или проде;
- Существенную часть хотфиксов этих багов забывали бэкпортить в более "ранние" ветки.
Плюс куча церемоний и задержек - каждый мёрж проходил через пайплайн сборки и тестирования, который занимал 5-10 минут.
Пострадав с этими проблемами, я начал думать над альтернативами.
Git Flow отмёл сразу, потому как там ещё больше церемоний, которые в нашем случае (единственная релизная версия) не нужны.
GitHub Flow меня отпугнул тем, что "по фэншую" предполагает Continuous Deployment, а мы к этому не готовы до сих пор.
Погуглив ещё, я нашёл OneFlow. Он мне показался разумным компромиссом между GitLab Flow и GitHub Flow и один спринт мы благополучно провели по нему.
А потом я решил, что "право имею" и придумал свой флоу - GitHub Flow с кодфризами и ручным деплоем.
Общая схема работы по нему следующая:
- Есть одна постоянная ветка - master;
- Разработчики создают фича ветки от master и мёржат их туда же;
- master автоматически деплоится на дев-стенд;
- На 7-ой день спринта я вешаю на master тэг vX-rc, объявляю код фриз и запрещаю разработчикам мёржи в master;
- QA гоняют тесты на деве;
- На 10-ый день спринта и после аппрува QA я вешаю на master тэг vX-release и деплою его на стейдж;
- На 11-ый день спринта я смотрю, как на стейдже прошли автотесты и что при этом в логах, и - если всё ок - деплою тег в прод.
Для хотфикса схема работы такая:
- Разработчик создаёт фича-ветку от тэга на проде;
- По готовности - деплоим эту ветку на стейдж;
- QA проверяют фикс и после аппрува я вешаю на ветку тэг vX.y-release и деплою его в прод;
- Фича ветка ребейзится на master и мёржится.
Тут ещё стоит сказать, что модель слияния у нас отчаянная - мы ведём линейную историю. То есть мёржи делаем через "fast forward" (ребейзим фича ветки на master перед мёржем), да ещё и со сквошем по умолчанию. Допускаю, что в один ужасный момент я пожалею об этой схеме, но последние полгода полёт нормальный и работать с историей стало существенно приятнее.
Выгрузки
Я сильно ошибся в оценке реализации пары фич. Это две схожие фичи в админке, которые позволяют просматривать списки пациентов и событий дневников. Казалось бы - что там делать?
Проблема с ними в том, что данные лежат в разных БД и их планируется много (уже сейчас 300к строк, прирост по 3к/сутки и скорость прироста увеличивается). При этом надо обеспечить стандартные фичи — пагинацию, сортировку по любому полю и фильтрацию по любому набору полей. Плюс по требованиям необходимо обеспечивать выгрузку в xlsx с лимитом на количество строк равным лимиту самого формата - чуть больше одного миллиона. В итоге мы руками сделали block nested loop join, о чём я чуть подробнее написал в отдельном микропосте.
В результате вместо запланированных 104 часов на эту работу ушло 176 часов.
Баги .net-бэка
При планировании я совсем не учитывал поддержку изначальной версии системы. И хотя разработка была заморожена и новых фич не было - несколько раз в kotlin-команду прилетали старые баги оригинальной системы, которые проявились только после появления реальных пользователей. Но нам повезло — багов было немного, они были простые и их исправление съело лишь несколько часов работы.
Стажёр
Посреди реинжиниринга мне пришлось уволить стажёра. Вообще, положа руку на сердце, её надо было уволить намного раньше, но я всё давал шансы. Пока она не пропала на несколько дней. И даже тогда я дал ещё один шанс, но, появившись на день, она тут же снова пропала и тут моё терпение лопнуло.
Удивительно (на самом деле нет) - но на скорость работы команды это никак не повлияло. Видимо, та польза, которую она приносила, полностью компенсировалась проблемами, которые она порождала в процессе работы - мучительно долгие ревью, больше количество ошибок, иногда код, который проходил только тесты, написанные для подтверждения его работоспособности, а не подтверждения его соответствия требованиям.
Факапы в проде
Для начала надо прояснить что я имею в виду под факапом и продом.
Под факапом я понимаю проблему конечных пользователей, с которой к нам пришёл заказчик.
Касательно прода - это окружение, которым пользуется заказчик и реальные пользователи, и у нас это не так страшно, как вы могли подумать. Первые два наиболее багоёмких месяца работы (ноябрь и декабрь 2022 года) реальных пользователей у нас не было - приложением, кроме команды разработки, пользовались буквально несколько человек со стороны заказчика и близких к нему врачей.
Реальные пользователи, в количестве ста человек, к нам пришли в начале января 2023 года. И далее был линейный рост примерно по сто человек в месяц. Соответственно, на момент окончания реинжирининга в апреле 2023 года у нас было порядка 400 человек реальных пользователей.
И под такое определение за весь реинжиниринг у нас подошли три ошибки.
Приглашение в наблюдатели
Первый факап в проде случился после первого же релиза нового бэка.
У нас есть функциональность приглашения пользователя в наблюдатели по емейлу. В оригинальном бэке она работала так:
- Сервис share идёт в сервис accounts и смотрит, зарегистрирован ли пользователь с таким емейлом;
- Сервис share отадёт команду сервису email-notifications на отправку емейла и включает в неё флаг accountExists
- Сервис email-notifications формирует ссылку, включающую этот флаг, и отправляет письмо на указанный емейл;
- Пользователь проходит по ссылке;
- Фронт смотрит на флаг и либо редиректит пользователя на форму ввода пароля, либо на главную/форму аутентификации.
И при реинжиниринге сервиса email-notifications, разработчик потерял "s" в имени поля флага в классе входящего DTO команды.
В результате ссылка всегда отправлялась с флагом равным false и приглашение в наблюдатели существующего пользователя ломалось.
Проблема дополнительно усугубилось тем, что в это же время и в этой же функциональности нашли и починили баг (или несколько - сейчас уже не могу раскопать) на фронте, и мы несколько дней разводили кто и где ошибся.
Поиск наблюдаемого
Второй факап у нас случился уже ближе к концу реинжиниринга.
У врача есть возможность искать своих пациентов. В старом бэке поиск выполнялся и по имени, и по логину. А при реинжиниринге в SQL-запросе поиска потеряли сравнение с именем пациента.
Соответственно, у врачей внезапно перестал работать привычный для них способ поиска.
Обработка протухших токенов
Последний релиз реинжиниринга у нас тоже отметился факапом.
МП у нас "реактивно" обновляют токены - выполняют обновление по 401-ой ошибке, а не до истечения срока его действия. А при реализации обновления токена разработчик пропустил, что библиотека работы с JWT выбрасывает исключение и в случае валидного, но протухшего токена.
И когда мы зарелизали функциональность обновления токенов на 400 реальных пользователей, их начало выбрасывать из приложения каждые 15 минут. А мы начали икать каждые 15 минут.
Бонус: аутентификация по куке
Это не совсем факап в проде по моему определению, так как его нашли наши QA. Однако и критичность, и "фейспалмность" его зашкаливают, поэтому я решил его включить в список.
У нас запросы к бэку аутентифицируются по JWT-токену. Но при настройке Spring Security я забыл отключить аутентификацию по куке. Соответственно, логаут на вэбе выглядел работающим, но не имел никакого эффекта. И когда следующий пользователь логинился со своими учётными данными - он получал доступ к аккаунту предыдущего пользователя.
Благо это было на самом начальном этапе реинжиниринга, когда у нас ни настоящих пользователей, ни настоящих данных ещё не было.
Примечательно, что первых трёх факапов можно было бы избежать, если бы мы придерживались принципов тестирования ЭП.
Факап с приглашением бы отловили, когда поняли, что тесты двух юз кейсов должны отличаться флагом в ссылке в письме, добавили бы забытую проверку и обнаружили, что один из них не проходит.
Факап с поиском очевидным образом бы отловил тест юз кейса поиска по имени.
Факап с протухшими токенами бы отловил негативный тест юз кейса обновления протухшего токена.
Результаты
Итого проект реинжиниринга длился ~5.5 месяцев с 31 октября 2022 года по 14 апреля 2023 года (дата релиза в прод фикса обновления токена). По Jira общие фактические трудозатраты на разработку, поддержку и коммуникации составили 1402.75 часа (175 человеко/дней).
В результате у нас получилось:
- 23,944 строк кода;
- 730 классов;
- 234 теста (преимущественно интеграционных);
- 100% покрытие эндпоинтов тестами;
- 93.2% покрытия строк кода тестами;
- 1:30 минут полное время сборки, включая все тесты кода, тесты архитектуры, detekt, сборку и верификацию покрытия кода;
- 84 баг, который нашли мы или QA;
- 3 бага, которые нашли пользователи или заказчик.
Стоило ли оно того? Безусловно да.
Через три месяца после завершения реинжиниринга я проанализировал задачи в Jira и написал об этом подробный пост. Главный вывод этого поста: после завершения реинжиниринга мы стали работать в два раза быстрее, в том числе за счёт того, что стали допускать в два раза меньше ошибок.
Выводы из всей истории
Что я буду делать по-другому в своём следующем проекте реинжиниринга:
- Сразу отслеживать прогресс в процентах;
- Закладывать больше времени на набор крейсерской скорости работы командой в первые два спринта;
- Следовать принципам тестирования Эргономичного подхода;
- Построю "карту тестирования" - какими юзкейсами/тест кейсами тестировать каждый эндпоинт;
- Декомпозирую задачи до размера в один (максимум три) дня;
- Заложу время на саппорт оригинальной версии системы;
- Внимательнее отнесусь к команде — кому можно доверять, кто с высокой вероятностью уволится, у кого какие планы на отпуск, и какой у меня есть кадровый резерв на случай выпадения человека.
Что я буду делать также в следующий раз:
- Работать по принципам Эргономичного подхода;
- Использовать те же принципы аргументации и структуру презентации при обосновании необходимости реинжиниринга;
- Планировать работы на базе графа зависимостей системы;
- Работать по спринтам;
- Вести дейлики по задачам, а не людям;
- Релизаться в прод как можно раньше и в целом следовать стратегии Strangler Fig.
На этом заканчивается организационно-менеджерская часть ретроспективы, и в следующем посте я расскажу как у нас устроен проект внутри.