Рациональный подход к декомпозиции систем на модули или микросервисы
April 15, 2023
Чего от разработки ПО хотят разработчики, продакты и владельцы бизнеса?
Одного и того же - побольше дофаминчика (гормон счастья), поменьше кортизольчика (гормон стресса). Притом источники и дофамина, и кортизола у них одни и те же. Дофамин вырабатывается, когда фичи выпускаются в срок и без багов, а кортизол - когда сроки срываются и вылазят баги и регрессии. Бизнесу будет ближе финансовая версия — срыв сроков и баги очевидным образом приводят к увлечению стоимости разработки. Что приводит к выбросу кортизола уже у владельцев.
Как обеспечить высокий уровень дофамина всей команды?
Для того чтобы поддерживать высокий уровень дофамина и низкий уровень кортизола у всех участников процесса, нам необходимо декомпозировать системы на модули. Декомпозиция помогает обеспечить высокую скорость и качество разработки за счёт:
- Ограничения объёма информации, которую надо осознать и закодировать на этапе первичной реализации функциональности;
- Ограничения объёма кода, который необходимо изучить и адаптировать к изменениям в требованиях;
- Исключения конфликтов при параллельной разработке независимых функций системы;
- Создания возможности независимого выпуска и развёртывания отдельных функций системы.
Однако, этого можно достичь, только в том случае, если получившиеся модули обладают высокой функциональной связанностью и низкой сцепленностью.
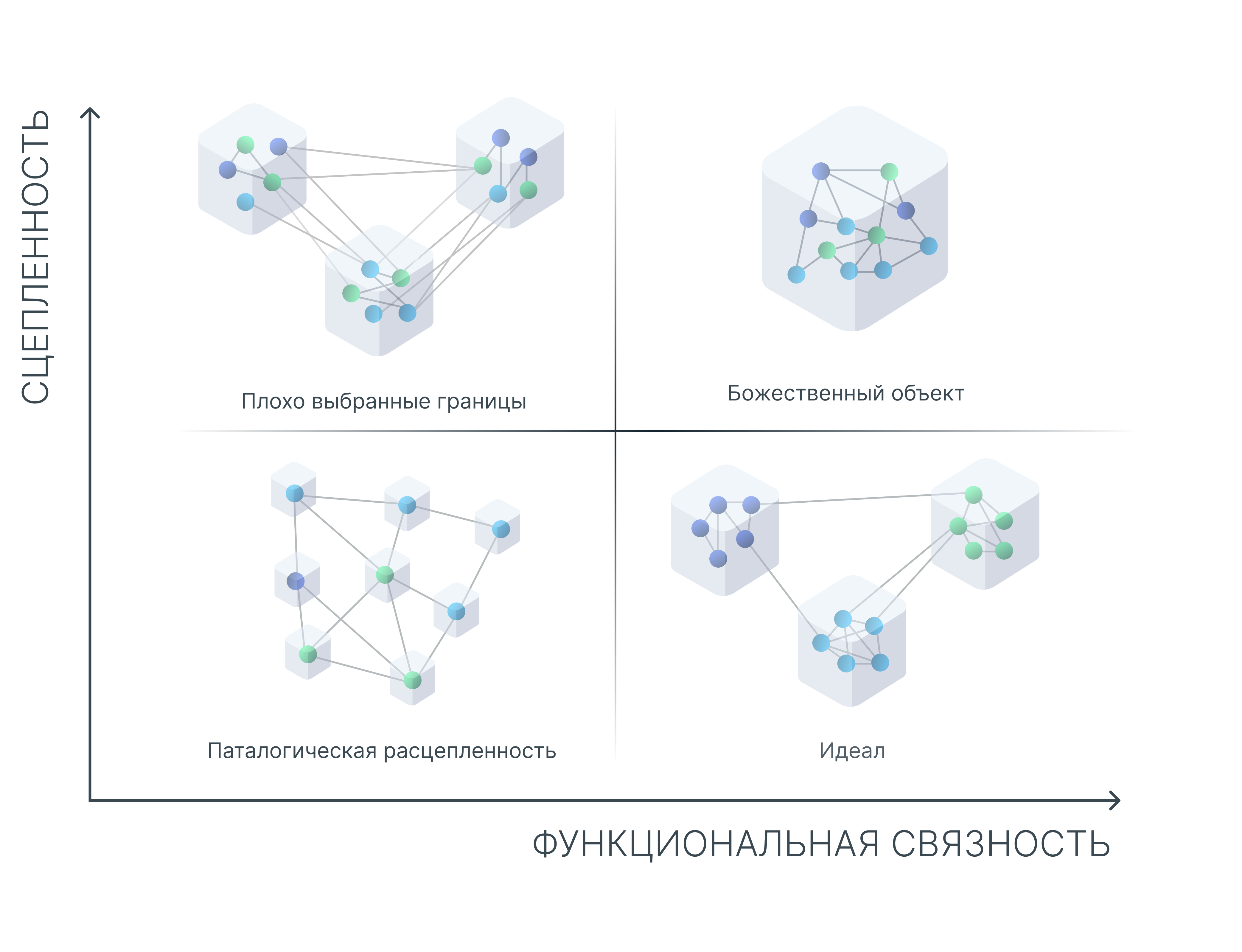
Кроме того, для максимизации выброса дофамина скорости разработки и минимизации выброса кортизола стоимости разработки, необходимо чтобы сама работа по декомпозиции системы проходила быстро и давала качественные результаты.
Как обеспечить высокий уровень дофамина всей команды при выполнении декомпозиции?
А для того чтобы эта работа проходила быстро и давала качественные результаты, необходимо, чтобы она была структурирована и стандартизирована. То есть нужна некоторая методика или рациональный подход к решению задачи декомпозиции. И тут у нашей индустрии есть проблемы.
По моему опыту, в ВУЗах декомпозиции либо не обучают совсем, либо обучают монструозным и фактически устаревшим методологиям вроде RUP-а. В других странах дела обстоят не лучше. Например, про ВУЗы США Джон Остерхаут пишет то же самое:
Problem decomposition is the central design task that programmers face every day, and yet, other than the work described here, I have not been able to identify a single class in any university where problem decomposition is a central topic. We teach for loops and object-oriented programming, but not software design.
Декомпозиция - это центральная задача проектирования, с которой программисты сталкиваются каждый день, и всё же, кроме работы, описанной здесь, я не смог определить ни одного курса ни в одном университете, где декомпозиция является центральной темой. Мы учим циклам и объектно-ориентированному программированию, но не проектированию ПО.
Из-за этого, в большинстве команд, которые я видел в последние годы, проектирование и декомпозиция заключалась в паре часов несистематизированного рисования прямоугольников и стрелок одним-двумя разработчиками. А полноценное проектирование и декомпозицию я видел в последний раз в 2005 году и они заняли несколько месяцев.
Для того чтобы обеспечить высокий уровень дофамина и на этапе проектирования и декомпозиции и на этапе последующей реализации, нам необходим подход к декомпозиции, который:
- Вообще есть;
- Прост в изучении;
- Прост в исполнении;
- Даёт хорошие результаты вне зависимости от исполнителя;
Это и будет тем самым рациональным подходом к декомпозиции, который нам необходим.
А что не так с классикой?
У опытного разработчика тут может возникнуть вопрос: "Зачем нужен очередной велосипед? Этих подходов к декомпозиции — тысячи!". Я честно проделал домашнюю работу, и перед тем как придумать собственный велосипед изучил более двадцати различных подходов к декомпозиции начиная с 60-ых годов, многое взял себе, но ни один из них мне не удалось положить свою на каждодневную практику.
Подробно основные распространённые сейчас подходы я рассмотрел в отдельном посте и здесь приведу только причины, по которым я не смог взять их в свою практику:
- Декомпозиция по слоям не масштабируется и даёт плохие результаты с точки зрения связанности и сцепленности;
- Декомпозиции по фичам и компонентам плохо описаны, и при попытке их применения возникает множество вопросов, на которые у источников нет ответов.
- DDD сложен и в изучении, и применении. Мне ни разу не удалось "продать" DDD хотя бы РП, фронтенд-разработчикам, аналитикам и QA-инженерам в собственной команде. Кроме того, наличие "на борту" экспертов предметной области, критически важное для DDD, в моей практике является скорее исключением, чем правилом.
Изучением и апробированием классики я занимался 6 лет - с 2014 до 2020 года. Так и не найдя внятного ответа на вопрос "Как мне декомпозировать систему?", во второй половине 2020 я начал искать собственный подход к декомпозиции и написал разделы книги о таблице эффектов и компонентах (осторожно, устаревшие и не редактированные черновики). К марту 2021 года я придумал объединить их в один граф и в итоге это превратилось в декомпозицию на базе эффектов.
Декомпозиция на базе эффектов
Концептуальная модель системы
Для того чтобы применить подход к декомпозиции на базе эффектов, систему необходимо представить в виде графа операций и элементов состояния, связанных эффектами чтения и записи. После чего процесс декомпозиции фактически сводится к кластеризации этого графа. Пока что создать полностью автоматический алгоритм кластеризации, который бы давал удовлетворительные результаты, мне не удалось, поэтому кластеризация выполняется вручную. И так как человеку проще выполнять кластеризацию графа, представленного визуально, я разработал специальную диаграмму, для представления графов эффектов.
Концептуальная модель системы и нотация диаграммы подробно описаны в спецификации. Упрощённо же можно считать, что:
- Операции — это эндпоинты REST API;
- Ресурсы — таблицы БД;
- Эффекты записи — SQL INSERT/UPDATE/DELETE запросы;
- Эффекты чтения — SQL SELECT-запросы.
Соответственно, для построения диаграммы эффектов надо для каждого метода API добавить на диаграмму по прямоугольнику светло-синего цвета, для каждой таблицы добавить по прямоугольнику тёмно-синего цвета, для каждого запроса модификации данных добавить красную стрелку между соответствующей операцией и ресурсом, а для каждого запроса чтения данных - синюю стрелку. В результате у вас получится картинка, состоящая из таких элементов:

Здесь, очевидным образом, операция "Зарегистрировать пользователя" вносит данные в таблицу "Пользователи", а операция "Аутентифицировать пользователя" считывает данные из этой таблицы. Процесс построения диаграммы эффектов реального проекта с примерами всех распространённых видов ресурсов и операций описан в посте Диаграмма эффектов: пример построения.
Также важно отметить, что все элементы диаграммы эффектов один в один транслируются в код:
- Операции — в методы классов сервисов приложения;
- Ресурсы — в классы сущностей и репозиториев (событий и топиков брокеров сообщений, DTO и клиентов REST API и т.д.);
- Эффекты — в вызовы методов классов репозиториев в методах классов сервисов.
После визуализации системы с помощью диаграммы эффектов необходимо выполнить её кластеризацию.
Кластеризация диаграммы эффектов
В основе подхода к кластеризации диаграммы лежит несколько простых идей:
- Ресурсы являются глобальными переменными;
- Между всеми модулями, которые взаимодействуют с одним ресурсом, появляется сцепленность через общее окружение (common environment coupling);
- Один из основных методов снижения сцепленности системы в целом - это локализация сцепленности через общее окружение внутри одного модуля;
- Запись глобальной переменной порождает большую сцепленность, чем чтение.
- В связях между модулями не должно быть циклов;
- Если модулю сложно дать хорошее имя, отражающее его содержание, это говорит о низкой функциональной связанности модуля.
То, что запись порождает большую сцепленность, чем чтение - может быть не очевидно. Однако это легко продемонстрировать, если рассмотреть их в контексте многопоточной работы. Считывать корректно опубликованную глобальную переменную могут сколь угодно много потоков без какой-либо синхронизации и проблем. Но, как только кто-то начинает изменять эту переменную, всё тут же становится намного сложнее: теперь надо обеспечить безопасный доступ и не создать дедлок, обеспечить протокол взаимодействия (сначала запись, потом чтение), следить за тем, чтобы операция записи не стала бутылочным горлышком в производительности системы и т.д.
Вооружившись этими идеями, легко определить требования к хорошей кластеризации диаграммы эффектов (декомпозиции системы):
- Между кластерами нет циклов;
- Эффекты записи (красные стрелки) инкапсулированы в одном кластере;
- Количество эффектов чтения (синих стрелок), пересекающих границы кластеров, минимально;
- Каждому кластеру легко дать имя, отражающее его содержание.
Для простых диаграмм такая кластеризация может быть видна на глаз. Примером простой диаграммы является диаграмма эффектов проекта True Story Project:
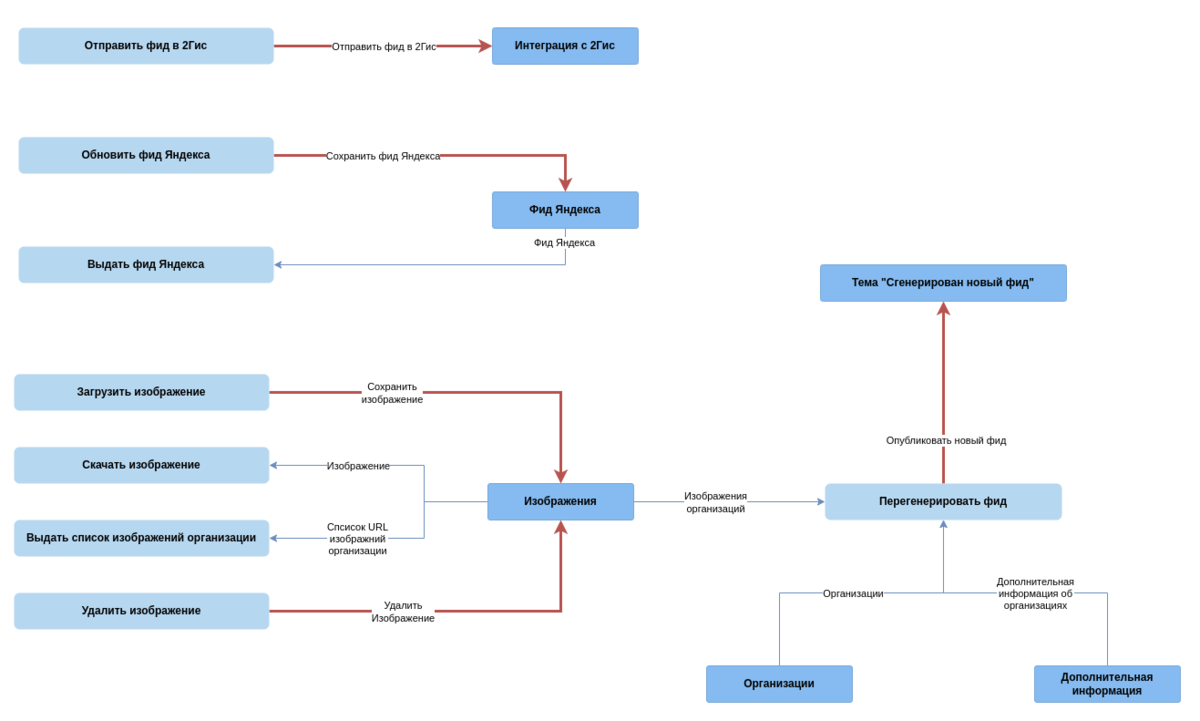
Здесь сразу же бросаются в глаза 3-4 кластера:
- Работа с изображениями;
- Формирование фида;
- Интеграция с 2Гис;
- Интеграция с Яндекс.Картами.
На этом примере хорошо видно, что интуитивная декомпозиция зависит и от разработчика диаграммы (как он расположит элементы) и от наблюдателя - я на этой диаграмме вижу 4 кластера, но некоторые люди "автоматически" объединяют интеграции в один модуль.
Кроме того, большие или запутанные системы на глаз кластеризовать не получится. Для того чтобы структурировать и ускорить процесс кластеризации таких диаграмм, а также снизить влияние исполнителя на результат, я разработал специальную методику.
Методика кластеризации диаграммы эффектов
Методика состоит из двух больших этапов — кластеризации и оптимизации кластеров. Для этапа кластеризации существует итеративный алгоритм, который простые диаграммы может кластеризовать полностью, а в сложных случаях - упросить и упорядочить рутинную работу, а также подсветить разработчику части системы, требующие особого внимания.
Общий алгоритм состоит из следующих шагов:
- Кластеризация
- Первичная кластеризация по алгоритму
- Генерация кластеров
- Расширение кластеров
- Агрегация ресурсов
- Завершение кластеризации вручную
- Первичная кластеризация по алгоритму
- Оптимизация
- Именование кластеров
- Визуализация графа кластеров
- Анализ графа кластеров
- Объединение кластеров (модулей)
- Сокрытие подмодулей
- Группировка функционально схожих кластеров
Алгоритм первичной кластеризации диаграммы эффектов
Алгоритм первичной кластеризации является итеративным, и каждая итерация состоит из трёх шагов:
- Генерация кластеров.
- Расширение кластеров.
- Агрегация ресурсов.
Генерация кластеров
Этап генерации кластеров заключается в том, чтобы перебрать все некластеризованные ресурсы и кластеризовать их с операциями, которые:
- Связаны только с этим ресурсом.
- Связаны с этим ресурсом своим единственным эффектом записи.
- Являются операциями чтения, для которых данный ресурс выступает первичным. Определение первичного ресурса (и вообще его наличия) остаётся на усмотрение исполнителя.
Расширение кластеров
Этап расширения кластеров - это самый простой и на 100% механический этап. Он заключается в том, чтобы перебрать все некластеризованные элементы, связанные только c элементами внутри одного кластера, и добавить их в этот кластер.
Агрегация ресурсов
Этап агрегации ресурсов заключается в том, чтобы оставшиеся некластеризованные ресурсы попытаться объединить в "разумные" группы между собой или с кластеризованными ресурсами. Строго говоря, на этапе агрегации надо перебрать все возможные попарные соединения и выбрать из них "разумные". Однако "разумные" пары, как правило, имеют общую операцию, поэтому эмпирический алгоритм агрегации выглядит так:
- Для каждого некластеризовнного ресурса выбрать ресурсы, с которыми у него есть общая операция.
Если в списке есть "разумная" пара данному ресурсу - сгруппировать их.
Формального критерия разумности у меня нет, но есть эмпирический. Группа является разумной, если удаление одного из ресурсов делает существование второго бессмысленным. Этот критерий может дать ложноотрицательный результат - если исходить только из него, то можно пропустить разумную группу ресурсов, которая, с учётом особенностей предметной области или ограничений системы, является таковой. Но c ложноположительными результатами - объединением в одну группу ресурсов, которое не является разумным - я в своей практике ещё не сталкивался.
Далее сгруппированные ресурсы рассматриваются как единое целое - все эффекты связывающие ресурсы этой группы с одной и той же операцией считаются одним эффектом. Если операцию связывают с группой и эффекты чтения и эффекты записи, то считается, что операция связана с группой эффектом записи.
После агрегации ресурсов снова возвращаемся к этапу генерации кластеров. Если на следующей итерации этапы генерации и расширения кластеров не привели к уменьшению количества некластеризованных элементов, то, теоретически, этап агрегации можно повторить и продолжать это делать до включения всех оставшихся ресурсов в одну группу. Однако практически уже на второй последовательной итерации агрегации (когда одна группа некластеризованных ресурсов содержит в себе три базовых ресурса) нужно быть начеку. Большие группы зачастую указывают на операции, которые делают слишком много работы и как следствие обладают высокой сцепленностью - в этом случае придётся вернуться к этапу проектирования самих операций и ресурсов.
В результате применения этого алгоритма вы получите либо полную, либо частичную кластеризацию. В случае если алгоритм зашёл в тупик и породил только частичную кластеризацию, её необходимо завершить вручную, основываясь на собственной экспертизе, понимании предметной области и ограничений проекта.
Ручное завершение кластеризации
При ручном завершении кластеризации сначала стоит попытаться закончить кластеризацию без внесения изменений в множества операций и ресурсов. Однако иногда первоначальные операции и ресурсы никак не укладываются в хорошие кластеры. В этом случае придётся изначальные операции и ресурсы немного доработать напильником.
Завершение кластеризации с сохранением базовой диаграммы
На этой стадии останутся некластеризованными только те элементы, которые связаны с двумя и более кластерами (в противном случае они бы были кластеризованы на шаге расширения кластеров). И тут, если сохранять исходную структуру диаграммы, есть три базовых варианта действий:
- Выделение в собственный кластер. Если элемент выглядит связанным со всеми кластерами в равной степени - его можно поместить в собственный кластер. В этот же кластер можно добавить другие элементы, связанные с теми же кластерами.
- Внесение в один из существующих кластеров. Если с одним из кластеров элемент связан бОльшим количеством связей или они кажутся "сильнее" - его можно внести в этот кластер. В случае операции стоит принять во внимание её клиента (внешнюю сущность, инициирующую выполнение операции) - если с одним из кластеров у неё общий клиент, то связь с этим кластером сильнее;
- Объединение в мегакластер. Если кластеры, связанные с элементом, имеют высокую функциональную связанность - их все можно объединить в один кластер.
При выборе варианта необходимо руководствоваться сцепленностью и функциональной связанностью дизайна. Для оценки сцепленности каждого варианта надо посчитать в релевантной части получившегося графа количество синих и удвоенное (для отражения их большей сцепляющей силы) количество красных стрелок, пересекающих границы кластеров. Полученное число и будет относительной оценкой сцепленности варианта. И при прочих равных лучше выбрать вариант с меньшим значением этого числа.
Если брать в расчёт только сцепленность, то наилучшим вариантом всегда будет третий вариант, сводящий количество стрелок, пересекающих границы кластера к нулю. Однако эта логика ведёт нас к абсурдному выводу: просто всё всегда объединять в один суперкластер с нулевой сцепленностью. И нулевой функциональной связанностью. А нашей же задачей является, разбить систему на набор модулей с низкой (не нулевой) сцепленностью и высокой функциональной связанностью.
Поэтому необходимо проверять ещё и функциональную связанность вариантов. Для этого каждому кластеру надо дать имя.
Если вы выбрали первый вариант (выделение в собственный кластер) и название кластера кажется слишком "низкоуровневым" — скорее всего вы идёте к патологической расцепленности и от выделения лучше воздержаться.
Если вы выбрали второй (поместить в существующий кластер) или третий вариант (объединить всё в один мегакластер) и дать получившемуся кластеру хорошее имя не получается — вы идёте к божественному объекту и лучше поискать другой вариант.
Если ни один из этих вариантов не даёт удовлетворительный на ваш взгляд результат, то придётся менять исходную диаграмму. Тут универсального алгоритма нет, но могу дать несколько рекомендаций, с которых можно начать поиск решения.
Завершение кластеризации с изменением базовой диаграммы
Для любых проблемных ресурсов в первую очередь надо рассмотреть вариант разделения их на несколько независимых ресурсов. Для этого надо проверить - все ли эффекты считывают/изменяют ресурс целиком или одну и ту же его часть? Или один из эффектов считывает только колонки A и B (из ресурса таблицы), а второй - C и D? В этом случае стоит рассмотреть вариант разделения таблицы (и ресурса) на две - с колонками A и B и C и D. Та же самая логика работает и для эффектов записи.
Операции записи можно попробовать кластеризовать с помощью расцепки через очередь сообщений. Для этого необходимо:
- Выделить основной эффект операции;
- Поместить операцию в кластер, с которым её связывает основной эффект;
- В тот же кластер добавить ресурс очереди сообщений для оповещения об основном эффекте;
- Добавить к исходной операции эффект записи по публикации сообщения в эту очередь;
- Все остальные эффекты отвязать от исходной операции;
- Отвязанные эффекты привязать к новым операциям в тех кластерах, ресурсы которых модифицируются этими эффектами и которые будут вызываться после публикации сообщения.
Расцепку изменяемых ресурсов также можно выполнить с помощью очереди сообщений и схожей процедуры:
- Выделить основной эффект на ресурс;
- Перенести ресурс в кластер, с которым его связывает основной эффект;
- В кластер второй операции добавить ресурс очереди сообщений о выполнении этой операции;
- В кластер основной операции добавить операцию, которая выполняет вторичный эффект и вызывается в ответ на появление сообщения в очереди из предыдущего пункта;
- У второй операции эффект на исходный ресурс заменить на эффект записи в эту очередь.
Для кластеризации ресурсов только на чтение можно рассмотреть вариант их дублирования. Для этого в каждом кластере, считывающим проблемный ресурс, надо создать копию исходного ресурса и эффекты чтения направить туда, а исходный ресурс удалить.
Наконец, операцию только на чтение можно попытаться кластеризовать комбинацией дублирования ресурсов и расцепкой через очередь сообщений. Для этого для каждого ресурса проблемной операции надо:
- Продублировать ресурс;
- В кластеры исходных ресурсов добавить ресурсы очередей сообщений о модификации ресурса;
- Ко всем операциям, имеющим эффект записи на ресурс, добавить эффект записи ресурса очереди сообщений;
- Для каждого дубля ресурса добавить операцию, обновляющую этот ресурс в ответ на появление сообщения в очереди;
- Эффект считывания ресурса проблемной операцией перенаправить на его дубль.
Это не исчерпывающий список возможных вариантов кластеризации проблемных элементов, однако эти способы достаточно часто работают. В крайнем случае, я надеюсь, они подтолкнут вас к открытию собственного варианта решения вашей проблемы.
После получения полной кластеризации можно переходить к этапу оптимизации кластеров.
Оптимизация кластеров
Этап оптимизации кластеров состоит из следующих шагов:
- Именование кластеров
- Визуализация графа кластеров
- Анализ графа кластеров
- Объединение кластеров (модулей)
- Сокрытие подмодулей
- Группировка функционально схожих модулей
На первом шаге каждому кластеру необходимо дать имя, отражающее его содержание. В случае хорошей декомпозиции - это не составит труда. Если же определить имя какого-то кластера не получается, то необходимо рассмотреть его внимательнее. Часто такие проблемы решаются с помощью разделения проблемного кластера на два более мелких и сфокусированных. Но поиск разумного имени кластера может привести и к перепроектированию ресурсов и операций.
После того как каждому кластеру дано разумное имя, надо построить визуализацию графа кластеров. Такая визуализация помогает увидеть "лес за деревьями" и оценить "разумность" уже самого леса.
Получив граф кластеров - проверьте его на соответствие вашему здравому смыслу. Я для этого фокусируюсь в первую очередь на связях и их направлении:
- Разумно ли, что этот модуль зависит от того?
- Может ли целевой модуль зависимости существовать без зависимого?
- Какой из модулей более стабилен (более стабильным должен быть целевой модуль)?
У вас могут быть свои вопросы для оценки соответствия здравому смыслу.
Наконец, последний шаг - найти и объединить подмодули и функционально схожие модули. Подмодуль - это модуль, обеспечивающий работу одного более высокоуровневого модуля. В этом случае кластер подмодуля необходимо поместить внутрь кластера модуля.
Функционально схожие модули - это модули, выполняющие разными способами одну и ту же функциональность, либо выполняющие разные подфункции одной общей функции. Такие модули надо объединить в общий кластер. Этому кластеру также надо дать имя и если это вызывает затруднения, то от объединения лучше отказаться.
Всё, теперь можно создавать структуру пакетов, соответствующую структуре кластеров, в каждом пакете создавать по классу сервиса со всеми операциями кластера и по классу репозитория/клиента/топика для каждого ресурса кластера.
На этом теоретическая часть закончена, но это только половина пути, поэтому я предлагаю вам прерваться, попить чаю и сделать разминку для глаз:)
Сделали? Теперь можно переходить к примеру.
Кейс: Кэмп
Примеры в программировании и особенно дизайне - это всегда боль. Слишком простые или синтетические не особо полезны. В реальные, со всеми их сложностями - мало кто станет вгружаться, кроме того, в них трудно отделить релевантные детали от шума. Кэмп является, на мой взгляд, золотой серединой.
Кэмп - реальный проект, который стоил семизначную сумму для заказчика, выполнялся командой из 12 человек (включая двух бакэндеров) и сейчас запущен в промышленную эксплуатацию. Суммарно на выполнение проекта было затрачено 5500 человеко/часов, из которых 950 - на бакенд.
Но есть нюанс - это был экспериментальный проект, который (с согласия заказчика) выполнялся силами исключительно молодых специалистов, а лиды только проводили ревью и помогали консультациями. Поэтому по фактическому объёму функциональности проект достаточно компактный.
Проект является специализированной геоинформационной системой для водителей-дальнобойщиков. В отличие от больших ГИС систем вроде Яндекс.Карт он отличается тем, что позволяет найти не просто гостиницу по дороге, а гостиницу где водитель может и сам переночевать и рефрижератор на 86 "кубов" припарковать.
Соответственно, двумя ключевыми сущностями являются водители и "точки" (кафе, заправки, СТО и т.п.). Точки в систему вносят сами пользователи после предварительной модерации. С водителями связаны характеристики машин, которые они водят (сейчас - только тип машины и размер колёс), а с точками - характеристики машин, которые они в состоянии обслужить.
Кроме того, в системе есть пуш-уведомления пользователей о новостях приложения, а также о результатах модерации добавленной точки.
Вся эта функциональность отражена на следующей диаграмме эффектов:

Теперь давайте прогоним алгоритм декомпозиции на базе эффектов на этой диаграмме и посмотрим что получится.
Кластеризация диаграммы эффектов проекта Кэмп
Напомню, общий алгоритм кластеризации диаграммы эффектов состоит из следующих шагов:
- Кластеризация
- Первичная кластеризация по алгоритму
- Генерация кластеров
- Расширение кластеров
- Агрегация ресурсов
- Завершение кластеризации вручную
- Первичная кластеризация по алгоритму
- Оптимизация
- Именование кластеров
- Визуализация графа кластеров
- Анализ графа кластеров
- Объединение кластеров (модулей)
- Сокрытие подмодулей
- Группировка функционально схожих кластеров
Этап кластеризации
Итерация 1, шаг генерации кластеров
На первом шаге надо перебрать все ресурсы и объединить их с сильно связанными с ними операциями. Перебирать будем в "естественном" порядке - сверху вниз, слева направо.
Поэтому начнём с ресурса "Сервис отправки СМС". С ним связана только операция "Запросить OTP", однако она сама связана эффектом записи с другим ресурсом, поэтому пока их откладываем.
То же самое с ресурсом "OTP" - он связан с операциями "Запросить OTP" и "Получить токен из отп", но обе операции имеют по два эффекта записи, поэтому этот ресурс также пока пропускаем.
Далее идёт ресурс "Токены". Его мы, наконец, можем объединить с операцией "Получить токен из логина/пароля" и получить первый кластер (на первом этапе я буду именовать кластеры по порядковому номеру их добавления на диаграмму). Операцию "Получить токен из отп" и в этом случае пока откладываем, так как она имеет два эффекта записи.
Теперь переходим к ресурсу "Пользователи". Этот ресурс является единственным для операций "Изменить пользователя" и "Удалить пользователя", а для операции чтения "Получить пользователя" он, очевидно, является первичным. Объединяем их все во второй кластер.
Затем рассмотрим схожие ресурсы "Типы машин" и "Размер колёс", оба ресурса связаны эффектами чтения с операциями чтения "Получить пользователя" и "Получить точки", но ни один из ресурсов не выступает первичным для этих операций, поэтому пока что пропустим их.
Теперь переходим к ресурсу "Топик 'Точка промодерирована'". Связанные с ним операции - "Удалить точку" и "Изменить точку" также связаны эффектами записи с другими ресурсами, поэтому этот ресурс пока что оставляем некластеризованным.
После чего переходим к ресурсу "Точки на карте". Он явно является первичным для операции чтения "Получить точки", а также единственным ресурсом операции "Создать точку". Объединяем их в третий кластер.
Далее у нас снова схожая пара ресурсов "Услуги" и "Тэги". Оба ресурса связаны своим единственным эффектом чтения с операцией "Получить точки", которая уже входит в третий кластер - отложим их до шага расширения кластеров.
Теперь переходим к подграфу уведомлений.
Тут у нас есть ресурс "Сервис отправки Push-уведомлений" с которым связаны операции "Создать новостное уведомление" и "Создать персональные уведомления", у которых по два эффекта записи, поэтому пока их все отложим.
Зато в четвёртый кластер мы можем объединить ресурс "Уведомления" с операциями "Удалить уведомление", "Получить список новостных уведомлений" (это их единственный ресурс) и "Получить список персональных уведомлений" (для этой операции чтения он является первичным).
Наконец, в пятый кластер можно объединить последний ресурс "Прочитанные уведомления" и операцию "Прочитать уведомление", для которой он является единственным ресурсом.
На этом шаг генерации кластеров заканчивается и у нас получается такая промежуточная кластеризация:

Итерация 1, шаг расширения кластеров
Далее идёт этап расширения кластеров, на котором все некластеризованные элементы, связанные только с одним кластером, надо поместить в этот кластер. У нас сейчас таких элементов два - ресурсы "Услуги" и "Тэги" связаны только с третьим кластером - затягиваем их в него (изменённый кластер обозначен пунктирной линией):

Итерация 1, шаг агрегации ресурсов
Теперь переходим к следующему шагу — агрегации ресурсов. Для этого перебираем оставшиеся некластеризованные ресурсы и смотрим, есть ли для них "разумная" пара, с которой они связаны общей операцией. Перебор снова будем делать в "естественном" порядке.
Поэтому начинаем с ресурса "Сервис отправки СМС". Он через операцию "Запросить OTP" связан с ресурсом "OTP". Начнём с эмпирического критерия разумности - теряет ли смысл существования один из ресурсов при удалении другого из системы. На данный момент - да. Сервис отправки СМС используется только для отправки одноразовых паролей, поэтому если удалить ресурс "OTP", то сохранять ресурс "Сервис отправки СМС" сохранять смысла не будет. Поэтому объединяем их в одну группу.
Затем идёт пара ресурсов "Типы машин" и "Размер колёс". И снова начинаем с эмпирического критерия разумности. На этот раз каждый из ресурсов есть смысл сохранить даже при удалении другого. Кроме того, группировка этих ресурсов никак не продвинет нас в кластеризации, поэтому эти два ресурса оставляем как есть.
Далее переходим к ресурсу "Топик 'Точка промодерирована'". Он через операции "Удалить точку" и "Изменить точку" связан с ресурсом "Точки на карте" и является механизмом оповещения об изменениях в последнем. Эти два ресурса мы группируем на основе эмпирического критерия разумности - если удалить коллекцию точек, то и оповещать будет не о чем.
Наконец, ресурсы "Сервис отправки Push-уведомлений" и "Уведомления". По эмпирическому критерию их не надо группировать - я могу засылать пуши напрямую и не хранить, или перейти к "пулл" уведомлениям. Однако на мой экспертный взгляд ни того ни другого не случится, а группировка этих ресурсов поможет мне продвинуть кластеризацию, поэтому эту пару я решаю агрегировать.
После выполнения всех этих агрегаций у нас получается следующий этап кластеризации (здесь агрегированные ресурсы обозначены штриховкой):

Теперь заходим на вторую итерацию и возвращаемся к шагу генерации кластеров.
Итерация 2, шаг генерации кластеров
На второй итерации генерации кластеров мы также проходимся по некластеризованным ресурсам, но теперь агрегированные ресурсы рассматриваем как одно целое. После агрегации ресурсов операция "Запросить OTP" стала связана одним эффектом записи с группой ресурсов "Сервис отправки СМС" и "ОТП" и теперь можно их кластеризовать:

После этого некластеризованными остались только ресурсы "Типы машин" и "Размер колёс", в отношении которых ничего не поменялось, поэтому переходим на следующий шаг.
Итерация 2, шаг расширения кластеров
После первой итерации шага агрегации ресурсов операции "Удалить точку" и "Изменить точку", а также "Создать новостное уведомление" и "Создать персональное уведомление" стали связаны только с элементами третьего и четвёртого кластера соответственно, поэтому теперь их можно затянуть в эти кластеры:

На этом алгоритм первичной кластеризации зашёл в тупик — операция "Получить токен из отп" связана двумя эффектами записи с разными кластерами, а ресурсы "Типы машин" и "Размеры колёс" связаны с разными кластерами двумя равноценными эффектами чтения. Пришло время расчехлить свой большой мозолистый мозг.
Этап ручного завершения кластеризации
Начнём с операции "Получить токен из отп". Как я писал в теоретической части, в этом случае у нас есть три варианта действий с сохранением изначальной структуры:
- Поместить в собственный кластер;
- Внести в шестой (первый) кластер;
- Объединить первый и шестой кластер и внести туда;
Визуально эти варианты выглядят так:

В целом, все эти варианты не выглядят очевидно бессмысленными и могут быть обоснованы. Но давайте рассмотрим их с точки зрения "тяжести" графа - пусть связь между кластерами синей стрелкой будет стоить одну единицу, а красной - две. В этом случае вес вариантов выше будет следующий:
- 6
- 4 (4)
- 2
Вполне предсказуемо, выигрывает вариант 3, который исключает все эффекты между рассматриваемыми кластерами. Теперь надо проверить связанность этого кластера, с помощью именования. На мой взгляд, выбор имени для этого кластера не составляет труда - всё что попало внутрь касается авторизации и только авторизации, поэтому кластеру отлично подходит имя "Авторизация".
Теперь у нас осталось только два некластеризованных элемента - ресурсы "Типы машин" и "Размеры колёс".
Для них три базовых варианта будут выглядеть так:
- Объединить их в собственный кластер;
- Внести во второй (третий) кластер;
- Объединить второй и третий кластер и внести туда;
Вес графов этих вариантов будет следующий:
- 4
- 2 (2)
- 0
Тут снова предсказуемо побеждает третий (объединить кластер с пользователями и точками в один мегакластер) вариант. Но этот вариант - просто сразу нет. Не думаю, что здесь надо что-то пояснять.
Далее по сцепленности идёт вариант с помещением этих ресурсов в один из существующих кластеров, но в обоих случаях эти ресурсы создадут проблемы с именованием итоговых кластеров.
Поэтому я выбираю третий вариант и помещаю их в собственный кластер. Пусть это будет вариант с наибольшей сцепленностью, зато - и с наибольшей функциональной связанностью всех трёх получившихся кластеров. А сцепленность, хоть и наибольшая - но на чтение, и на неё можно посмотреть сквозь пальцы. Наконец, у нас вся система про то, чтобы матчить пользователей с точками, на основании характеристик машин - об этом стоит явно сказать на верхнеуровневой структуре модулей.
В итоге я получаю следующую первичную кластеризацию:

И теперь мы можем переходить к этапу её оптимизации.
Этап именования кластеров
На этом этапе мы по очереди рассматриваем кластеры и даём им имена, отражающие их содержимое.
Так, для кластера с элементами "Запросить OTP", "Сервис отправки СМС", "OTP", "Получить токен из отп", "Токены" и "Получить токен из логина/пароля" на мой взгляд отлично подходит имя "Авторизация".
Для кластера с элементами "Пользователи", "Изменить пользователя", "Удалить пользователя" и "Получить пользователя" - подходит имя "Пользователи".
Кластер с элементами "Типы машин" и "Размер колёс" можно назвать "Характеристики машин".
Самому большому кластеру с элементами "Точки на карте", "Топик результатов модерации", "Создать точку", "Удалить точку", "Изменить точку", "Получить точки", "Услуги", "Тэги" можно дать имя "Точки".
Затем кластеру с элементами "Уведомления", "Сервис отправки Push-уведомлений", "Создать новостное уведомление", "Создать персональное уведомление", "Удалить уведомление", "Получить список новостных уведомлений", "Получить список персональных уведомлений" подходит имя "Уведомления".
А вот для последнего кластера с элементами "Прочитанные уведомления" и "Прочитать уведомление" имя "Прочитанные уведомления" хоть и подходит, но меня заставляет поморщиться. Это слишком низкоуровневая штука, для верхнеуровневой структуры модулей.
Быстрым решением будет объединить этот кластер с кластером "Уведомления". Однако меня эта нестыковка вывела на другое решение.
Напомню, что в системе есть два вида уведомлений - персональные и новостные. На данный момент они хранятся в общем ресурсе - "Уведомления". И я задумался - а что общего у персональных и новостных уведомлений?
На самом деле - практически ничего.
Флаг прочтения есть только у персональных уведомлений. Уведомления отправляются разными экторами в разное время - персональные отправляются системой автоматически, а новостные - по запросу администратора. Они отправляются разным людям - персональные отправляются водителю, создавшему точку, а новостные - всем водителям. Даже методы API для отправки используются разные.
И так я пришёл к тому, что у меня была ошибка в изначальном дизайне - ресурсы "Уведомления" и "Сервис отправки Push-уведомлений" надо было разделить на два - для персональных и новостных уведомлений. И если это сделать, то всё сразу встаёт на свои места - этим двум новым кластерам легко дать имена "Новостные уведомления" и "Персональные уведомления" и они будут уже не так сильно выбиваться по уровню абстракции:

Теперь мы можем переходить к шагу анализа графа кластеров.
Этап анализа графа кластеров
На этом этапе первым делом необходимо этот граф визуализировать. Это та самая "верхнеуровневая структура модулей", на которой сразу видно элементы, выпадающие по уровню абстракции.

При анализе я в первую очередь смотрю на зависимости.
Разумно ли, что авторизация зависит от пользователей? Мне кажется разумно - мы же пользователей авторизуем.
Разумно ли, что пользователи и точки зависят от характеристик машин? Мне кажется разумно - характеристики машин являются абстрактными понятиями, характеризующими машины конкретных пользователей и конкретные точки.
Затем я проверяю, что все элементы графа имеют один уровень абстракции. И на мой взгляд "Новостные уведомления" и "Персональные уведомления" выпадают по уровню абстракции. А вот если их спрятать в более абстрактном модуле "Уведомления" - всё встанет на свои места.
И это даёт нам итоговую декомпозицию системы на пять верхнеуровневых модулей:

На этом декомпозиция системы завершена - можно создавать проект, там заводить по пакету (или модулю) на каждый кластер, в каждом пакете создавать класс сервиса, для каждой операции кластера в соответствующем классе определять метод и вперёд, можно кодировать.
Подход проверен и обоснован научно
Всё, что я описал выше - и саму концепцию декомпозиции на базе эффектов, и диаграмму эффектов и методику декомпозиции - я придумал сам долгими вечерами и ночами. А потом нашёл три научных статьи, описывающих такой же по сути подход:
Я не буду здесь подробно останавливаться на этих статьях - они в открытом доступе и заинтересованный читатель может изучить их самостоятельно - приведу лишь главный, с моей точки зрения, тезис:
The evaluation results give us reasons to believe that our approach identifies microservices in a quality that is comparable to a design done by human software designers. Our approach, however, achieved the microservices identification much faster and with less effort compared to human developers. While identifying the microservices was a matter of days for the students at KIT and SWU-RISE, by employing our approach it was a matter of hours.
Результаты оценки дают нам основания полагать, что наш подход выявляет микросервисы, качество которых сравнимо с дизайном, выполненным людьми. При этом наш подход позволяет выявлять микросервисы гораздо быстрее и с меньшими усилиями по сравнению с выполнением этой работы вручную. В то время как у студентов KIT и SWU-RISE выявление микросервисов потребовало несколько дней, с использованием нашего подхода это заняло несколько часов.
Ограничения подхода к декомпозиции на базе эффектов
Но серебряных пуль не бывает и декомпозиция на базе эффектов также не является таковой и имеет свои ограничения.
Чтобы выполнить декомпозицию на базе эффектов, необходимо построить диаграмму эффектов. А для этого надо весьма подробно понимать, что и как надо сделать. А для этого надо техзадание. Соответственно, если у вас нет ТЗ - выполнить декомпозицию на базе эффектов не получится.
Но в этом случае можно сделать финт ушами. Начать программировать с любой декомпозицией - хоть по слоям. А потом, когда станет понятно что вы делаете и у вас накопится какой-то объём кода, выполнить обратный процесс - построить диаграмму эффектов по коду. Её уже декомпозировать и потом отрефакторить код в соответствии с результатом декомпозиции.
Также стоит иметь в виду, что этот подход всё ещё находится на стадии опытной эксплуатации, и максимальный размер проекта, который я по нему декомпозировал, составляет один человеко-год. Но с другой стороны, я не могу представить, чтобы кто-то в 2023 году сразу проектировал систему на десять человеко-лет вперёд. Скорее всего, вы и так пойдёте небольшими итерациями в год максимум, и на таком масштабе декомпозиция на базе эффектов отлично работает.
Наконец, с точки зрения типа и характера задач, подход на базе эффектов хорошо подходит для декомпозиции систем с богатым состоянием и правилами его изменения. Если же в системе состояния как такого немного — такую систему декомпозировать на базе эффектов уже не получится. В компиляторах, например, из ресурсов будет только коллекция исходников, из операций - "Скомплировать" и всё, декомпозировать нечего.
Характеристики подхода к декомпозиции на базе эффектов
Итак, для того чтобы максимизировать количество дофамина и минимизировать количество кортизола в команде, нам нужен подход к декомпозиции, который обладает следующими характеристиками:
- Вообще есть;
- Прост в изучении;
- Прост в исполнении;
- Даёт хорошие результаты вне зависимости от исполнителя;
Обладает ли подход к декомпозиции на базе эффектов этими характеристиками?
Во-первых, он безусловно есть.
Во-вторых и третьих, для меня он существенно проще в изучении и исполнении чем DDD. Является ли он таковым для вас - судить вам. Вы можете попробовать его применить в своём проекте или его небольшой части - это займёт немного времени, и вне зависимости от результатов поможет вам лучше понять свою систему. По моему опыту трудозатраты на декомпозицию на базе эффектов идут в соотношении 1-2 человеко/часа проектирования к 1 человеко-месяцу разработки. Соответственно, со скидкой на отсутствие опыта, на декомпозицию проекта на 2 человеко-месяца вам должно хватить одного человеко-дня.
Наконец, результаты декомпозиции на базе эффектов всё-таки зависят от исполнителя, но в меньшей степени, чем интуитивная декомпозиция или декомпозиция на базе границ в языке предметной области.
В итоге по своему опыту могу сказать, что подход к декомпоизиции на базе эффектов действительно помогает максимизировать количество дофамина (и минимизировать количество кортизола) от разработки и для команды и для бизнеса.