Абстрактные войны: public interface IAbstraction против абстракции
July 6, 2022
Введение
Почти 30 лет назад в классической книге по шаблонам проектирования Design Patterns: Elements of Reusable Object-Oriented Software, авторы сформулировали один из самых известных, но недопонятых принципов в истории программирования:
Program to an interface, not an implementation.
Зачем "программировать в интерфейсы"? Для того чтобы реализацию этого интерфейса можно было менять без изменений клиентского кода.
Далее авторы объясняют как следовать этому совету:
Don’t declare variables to be instances of particular concrete classes. Instead, commit only to an interface defined by an abstract class.
Многие воспринимают это буквально и просто вносят в программу дополнительную сущность (интерфейс или абстрактный класс), которая дублирует список и сигнатуры методов одного конкретного класса.
Проблема в том, что использование ключевого слова abstract или interface само по себе не создаёт абстракцию и не защищает клиента от изменения реализации. Зато эти "заголовочные интерфейсы" по капельке, но каждый день подъедают человеческие, машинные и временные ресурсы.
Поэтому в Эргономичном подходе я отказался от повсеместного использования интерфейсов и применения принципа инверсии зависимостей по умолчанию.
Давайте рассмотрим на примере вымышленной истории, почему использование ключевого слова interface не является ни достаточным, ни необходимым для защиты клиентского кода от смены реализации интерфейса.
А потом увидим, насколько легко превратить конкретный класс в интерфейс и добавить новую реализацию, если он описывает абстракцию.
Наконец, рассмотрим несколько эвристик, которые помогают создавать классы описывающие абстракции, а не реализации.
Эпизод первый: Скрытая угроза. Интерфейсы.
Представим, что некий молодой архитектор Артемий начинает новый проект. Так как бизнес требует от него минимизировать "time to market", он решает, что собрать на коленке прототип будет быстрее всего на базе Spring Data JPA. Но он будет "программировать в интерфейсы", чтобы быстро всё переписать на более поддерживаемую технологию, если проект стрельнет.
Артемий пишет примерно такой код:
package pro.azhidkov.programtointerfaces.v1
import org.springframework.data.repository.CrudRepository
import javax.persistence.Entity
// ...
@Entity
class User(
@Id var id: Long,
var login: String,
var password: String
)
@Repository
interface UsersRepo : CrudRepository<User, Long>
@Service
class UsersService( // тут по идее тоже должен быть интерфейс, но сократим его ради экономии места
private val usersRepo: UsersRepo
) {
@Transactional
fun updatePassword(id: Long, newPass: String) {
val user = usersRepo.findByIdOrNull(id)
user.password = newPass
}
}Казалось бы, всё восхитительно - мы не завязываемся ни на какие детали реализации и в любой момент сможем сменить технологию работы с БД, да и сам тип БД.
И когда приложение перерастает штанишки прототипа, Артемий, решив перейти на Spring Data JDBC, просто меняет зависимость в скрипте сборки, делает замену по проекту "@Entity" на "@Table@" и… О чудо! Всё собирается!
Однако, после поспешного релиза в прод выясняется, что ничего не работает. Точнее в режиме чтения приложение работает, а вот никакие модификации не сохраняются. После судорожного отката релиза и суток дебага, Артемий в документации к Spring Data JDBC выясняет, что она не реализует такую "небольшую деталь" как Dirty Checking и автомагически ничего не сохраняет. Тогда Артемий везде добавляет *Repo.save() и всё, кризис преодолён.
package pro.azhidkov.programtointerfaces.v2
import org.springframework.data.relational.core.mapping.Table
import org.springframework.data.repository.CrudRepository
// ...
@Table
class User(
var id: Long,
var login: String,
var password: String
)
@Repository
interface UsersRepo : CrudRepository<User, Long>
@Service
class UsersService(
private val usersRepo: UsersRepo
) {
@Transactional
fun updatePassword(id: Long, newPass: String) {
val user = usersRepo.findByIdOrNull(id)
user.password = newPass
usersRepo.save(user)
}
}Правда эта правка превратит код Артемия в анти-паттерн с точки зрения JPA🤦.
Так на своём горьком опыте Артемий узнал, что одно только использование интерфейсов не гарантирует изменение реализации, без изменения клиентов.
Когда проект ещё подрос, и возникла потребность в реактивном подходе, Артемий уже понимал, что переход на Spring Data R2DBC будет долгим и тяжёлым. Осознав, насколько кодовая база заточена на синхронную работу, вместо миграции проекта на Spring Data R2DBC, Артемий решил сам мигрировать на новый проект.
Эпизод второй: Пробуждение силы. Абстракции.
Наученный горьким опытом, Артемий понял, что "программирование в интерфейсы" само по себе ничего не даёт с точки зрения гибкости. Зато интерфейсы занимают место на экране, диске и в голове Артемия. А также увеличивают время компиляции проекта. И усложняют навигацию по коду и его рефакторинг.
Поэтому в новом проекте Артемий решил программировать без лишних церемоний, зато с учётом всего своего опыта. На этот раз Артемий отложил выбор технологии для работы с БД и начал с тривиальных suspend-репозиториев неизменяемых сущностей на базе ассоциативных массивов:
package pro.azhidkov.programtointerfaces.v3
import org.springframework.stereotype.Repository
import org.springframework.stereotype.Service
import org.springframework.transaction.annotation.Transactional
class User(
val id: Long,
val login: String,
val password: String
)
@Repository
class UsersRepo {
private val data = HashMap<Long, User>()
suspend fun findByIdOrNull(id: Long): User? = data[id]
suspend fun save(user: User) {
data[user.id] = user
}
}
@Service
class UsersService(
private val usersRepo: UsersRepo
) {
@Transactional
suspend fun updatePassword(id: Long, newPass: String) {
val user = usersRepo.findByIdOrNull(id)
val updatedUser = user.copy(password = newPass)
usersRepo.save(updatedUser)
}
}Начав работать в таком стиле, Артемий каждый день радовался как ребёнок тому, что теперь не приходится постоянно возиться с чёртовыми прицепами в виде интерфейсов.
Однако, когда пришёл день Д - день выбора технологии работы с БД - Артемий по старой памяти напрягся. У нового проекта не ожидалось большого количества пользователей, поэтому Артемий снова решил использовать Spring Data JDBC. Кроме того, имеющиеся in-memory репозитории решили сохранить для использования в демо-версии продукта.
"Вот бы у нас сервисы зависели от интерфейсов репозиториев, чтобы мы могли во время исполнения выбирать реализацию" - злорадно говорили адепты карго культа "program to interface" из команды Артемия.
Однако, Артемий хорошо владел своими инструментами и знал, что класс, описывающий хорошую абстракцию, с помощью рефакторинга extract interface превращается в тот самый интерфейс лёгким движением руки.
Правда для Kotlin, в отличие от Java, у этого рефакторинга ещё нет галки "use interface where possible"🤦♂️. Но всё равно можно вытащить интерфейс, а потом без рефакторинга просто поменять местами имена интерфейса и класса:
- С помощью рефакторинга из класса UsersRepo вытащить интерфейс IUsersRepo
- Без рефакторинга в файле IUsersRepo.kt заменить текст "IUsersRepo" на "UsersRepo"
- Без рефакторинга в файле UsersRepo.kt заменить текст "UsersRepo" на "InMemUsersRepo"
- Без рефакторинга переименовать файл UsersRepo.kt в InMemUsersRepo.kt
- Без рефакторинга переименовать файл IUsersRepo.kt в UsersRepo.kt
Следующая проблема. Артемий перестраховался и везде добавил suspend, который стал лишним, т.к. Spring Data JDBC работает в блокирующем режиме. Хорошо, что ломать не строить. Можно воспользоваться структурной заменой для того, чтобы найти и удалить все модификаторы suspend у методов классов заканчивающихся на "Repo":
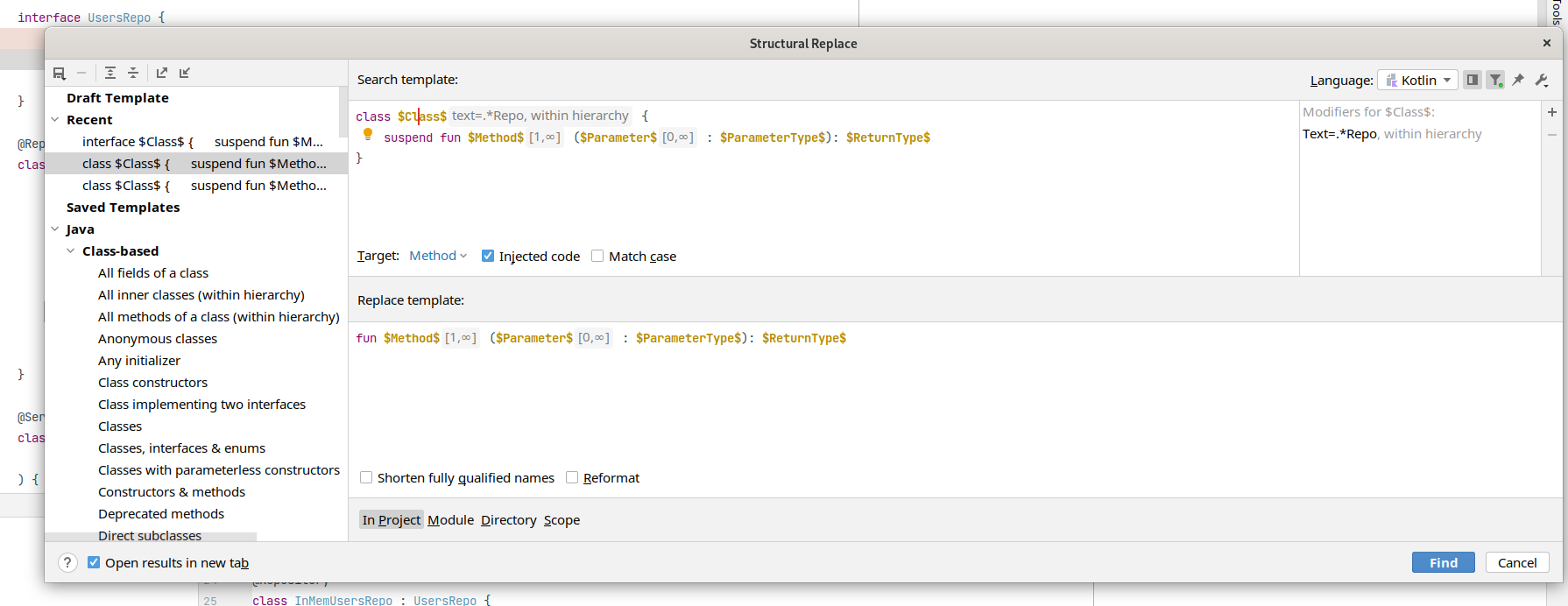
Потом то же самое надо проделать для интерфейсов. Поэтому лучше загодя подумать об этом и сначала убрать suspend, а потом выделить интерфейс. В итоге у Артемия получился такой код:
package pro.azhidkov.programtointerfaces.v4
import org.springframework.stereotype.Repository
import org.springframework.stereotype.Service
import org.springframework.transaction.annotation.Transactional
class User(
var id: Long,
var login: String,
var password: String
)
interface UsersRepo {
fun findByIdOrNull(id: Long): User?
fun save(user: User)
}
@Repository
class InMemUsersRepo : UsersRepo {
private val data = HashMap<Long, User>()
override fun findByIdOrNull(id: Long): User? = data[id]
override fun save(user: User) {
data[user.id] = user
}
}
@Service
class UsersService(
private val usersRepo: UsersRepo
) {
@Transactional
suspend fun updatePassword(id: Long, newPass: String) {
val user = usersRepo.findByIdOrNull(id)
val updatedUser = user.copy(password = newPass)
usersRepo.save(updatedUser)
}
}Теперь Артемий может спокойно добавить "реализации" с помощью Spring Data JDBC и у него всё будет работать.
На этом история Артемия благополучно заканчивается. А нам ещё надо сделать орг. выводы.
Эпизод третий: Последние джедаи. Эргономичный подход к абстракции.
Именно потому что сами по себе интерфейсы ничего не гарантируют, а тщательно спроектированные классы превращаются в интерфейсы одним движением руки, в Эргономичном подходе я отказался от повсеместной инверсии зависимостей и внедрения интерфейсов.
Вместо этого я слежу за утечками абстракций в интерфейсах классов (имени класса и сигнатурах методов) и применяю функциональную архитектуру.
Отслеживания требуют два основных вида утечек - явные и неявные.
Явные утечки
Явные утечки в свою очередь тоже бывают двух типов - в именовании и типах параметров.
Для того чтобы класс описывал абстракцию, внезапно надо, чтобы имена самого класса, методов и параметров были максимально абстрактными. Например, в True Story Project за отправку фида в 2Гис по Email у меня отвечает такой класс:
class DGisFeedSender {
// Поля и конструктор
public void sendFeedTo2Gis(String recipient, String subject, InputStreamSource inputStreamSource) {
// ..
}
}Как видно, в этом коде никак не упоминается Email, и я могу переделать его на отправку в телеграм, например, не трогая интерфейс или его клиентов. Или лёгким движением руки (и т.к. в этом проекте у меня Java - это будет действительное лёгкое движение) выделить интерфейс и сделать механизм отправки конфигурируемым.
Бывают ситуации, когда я предвижу смену или появление новой реализации и сразу завожу интерфейс. Например, я бы так поступил на месте Артемия во втором проекте.
В этом случае повысить качество абстракции мне помогает другое правило - я не пользуюсь префиксами/суффиксами I/Impl/Abstract/Default и им подобным. Интерфейсы я называю абстрактно, а в классы реализации добавляю что-то (прилагательное, название технологии и т.п.), характеризующее суть реализации. Так в примере Артемия у меня был бы интерфейс UsersRepo, который реализуется (в кавычках для Spring Data) интерфейсом SpringDataUsersRepo и классом InMemUsersRepo.
И если у меня появляются проблемы с выбором имени класса или интерфейса - для меня это красный флаг, указывающий на проблемы в дизайне.
Что касается типов - я слежу за тем, чтобы через параметры и результаты методов не утекали типы, использованные в реализации. Например, в Проекте Л мне среди прочего надо было реализовать "подглядывающие" проксирование HTTP-запросов. Метод проксирования у меня очевидным образом получал HTTP-запрос и возвращал HTTP-ответ. И хотя я мог взять эти классы из библиотеки реализации (ktor) я их обернул в собственные типы:
data class HttpRequest(
val method: String,
val path: String,
val query: Map<String, List<String>>,
val headers: Map<String, List<String>>,
val body: String?
)
data class HttpResponse(
val status: Int,
val headers: Map<String, List<String>>,
val bodyBytes: ByteArray
)
suspend fun ApiClient.proxy(token: String, request: HttpRequest): HttpResponse {
// ...
}При разборе одной из ошибок, это позволило мне быстро попробовать подменить реализацию на Spring WebClient, чтобы попытаться её обойти (в итоге остался на ktor). Если бы я завёл для класса заголовочный интерфейс, но вытащил туда типы из ktor-а - этот фокус у меня не удался. Поэтому между генераций "лишних" интерфейсов и "лишних" типов я голосую за вторые.
Тут важно не перегнуть палку. Например, Spring Data даёт много чудесной автомагии, если использовать класс Pageable. Если же вместо него использовать собственный класс, то придётся написать гору ручного кода для реализации пагинации. А миграцию своих проектов со Spring на что-то другое я считаю практически невероятной, поэтому использую Pageable в интерфейсах классов без зазрения совести.
Неявные утечки
По моему опыту, наиболее проблемные неявные утечки связаны с одним предположением, проявляющемся в двух аспектах. Само предположение - "сервер" (реализация зависимости) находится в одном адресном пространстве/процессе с "клиентом".
С одним из аспектов этого предположения - достаточностью простого присвоения нового значения полю изменяемого объекта в клиенте для того, чтобы оно изменилось на сервере - мы уже столкнулись в истории Артемия. Ровно ту же проблему Артемий бы получил, если бы по каким-то причинам решил заменить реализацию репозиториев на работу через REST API, например.
С этим аспектом отлично борются неизменяемые структуры данных, которые вообще несут много светлого и доброго в дизайн. Поэтому я сам повсеместно и по умолчанию использую неизменяемые структуры данных, требую этого от своей команды и всячески продвигаю их в интернете.
Ко второму аспекту Артемий тоже подошёл, но решил его избежать. Суть этого аспекта, заключается в полагании на простоту внутрипроцессного взаимодействия. Внутрипроцессное взаимодействие является моментальным (на фоне межпроцессного) и сам вызов наверняка дойдёт до адресата, а ответ наверняка вернётся. Если же адресат окажется в другом процессе (или того хуже на другой машине), то у нас тут же возникают все проблемы, свойственные распределённому программированию, которые никак не отражаются в упрощённом интерфейсе.
Для того чтобы обеспечить себе возможность безболезненного перехода с внутрипроцессного на межпроцессное взаимодействие, интерфейс надо существенно усложнить. Как минимум стоит рассмотреть вариант suspend/reactive интерфейса. В зависимости от контекста может быть смысл вытащить в интерфейс и потенциальные инфраструктурные ошибки.
Это всё довольно сильно усложняет код, поэтому к абстрагированию от местонахождения зависимости я прибегаю только в том случае, если считаю вероятность отъезда зависимости в другой процесс "достаточно высокой".
Вообще, самое лучшее практическое руководство по созданию нетекущих абстракций, которое я читал, содержится в книге Practical API Design: Confessions of a Java Framework Architect. Это 400 страниц квинтэссенции боли и страданий от последствий ошибок, допущенных её автором (главным архитектором NetBeans) при проектировании "ядерных" абстракций IDE.
Функциональная архитектура
Проектирование хороших абстракций решает проблему гибкости системы, однако остаётся проблема статической привязки домена к инфраструктуре. Для решения этой проблемы Эргономичный подход полагается на функциональную архитектуру - выделение домена в чистое ядро, которое на самом деле не зависит ни от чего ни во время компиляции, ни во время исполнения.
В качестве иллюстрации возьму пример из проекта хранения информации о торговле на бирже крипто-валют.
Там был такой пример плохой реализации (немного подправил под контекст этого поста):
fun updateCustomerSymbols(customerId: Long, activeSymbols: List<ActiveSymbol>) {
val customerSymbols = customerSymbolsRepo.fetchCustomerSymbols(customerId)
// Доменная логика суть которой не так важна в этом посте и описана в посте про агрегаты
activeSymbols.map { activeSymbol ->
val trading = customerSymbols.tradings.find { it.symbol == activeSymbol.symbol }
if (trading != null) {
trading.activeGrid = trading.grids.find { it.name == activeSymbol.gridName } ?: Grid(activeSymbol.gridName, BigDecimal(0))
} else {
val activeGrid = Grid(activeSymbol.gridName, BigDecimal(0))
customerSymbols.tradings.add(
SymbolTrading(activeSymbol.symbol, mutableListOf(activeGrid), activeGrid)
)
}
}
customerSymbolsRepo.save(customerSymbols)
}Даже если customerSymbolsRepo - интерфейс, доменная логика всё равно сильно сцеплена с вводом-выводом и её сложно переиспользовать в другом контексте. Примером "другого контекста", который всегда актуален для доменной логики, являются тесты.
И хотя интерфейс существенно упрощает тестирование бизнес-логики, за счёт того, что позволяет в тестах использовать фейковый репозиторий, мы можем намного лучше.
Если вынести логику в отдельные чистые функции:
data class SymbolTrading private constructor(
val symbol: Symbol,
val grids: Map<GridName, Grid>,
val activeGrid: GridName
) {
fun activateGrid(gridName: String): SymbolTrading =
if (gridName in grids) SymbolTrading(symbol, grids, gridName)
else SymbolTrading(symbol, grids + (gridName to Grid(gridName)), gridName)
}
data class CustomerSymbols(
val customerId: Long,
val tradings: Map<Symbol, SymbolTrading>
) {
fun activateSymbols(activeSymbols: List<ActiveSymbol>): CustomerSymbols {
val updatedTradings = activeSymbols.map {
tradings[it.symbol]?.activateGrid(it.gridName)
?: SymbolTrading.new(it.symbol, it.gridName)
}
return CustomerSymbols(customerId, tradings + updatedTradings.associateBy { it.symbol })
}
}
fun updateCustomerSymbols(customerId: Long, activeSymbols: List<ActiveSymbol>) {
val customerSymbols = customerSymbolsRepo.fetchCustomerSymbols(customerId)
val updatedCustomerSymbols = customerSymbols.activateSymbols(activeSymbols)
customerSymbolsRepo.save(updatedCustomerSymbols)
}то тестирование бизнес-логики становится просто вызовом функции и проверкой результата. А изолированно тестировать оркестрацию (метод updateCustomerSymbols) особого смысла нет - ошибки в нём могут быть только на границах модулей, он будет исчерпывающе протестирован любым сценарным тестом, а любой юнит-тест с моками будет тавтологией.
Функциональная архитектура помогает расцепить только бизнес-логику и инфраструктуру, и если не предпринимать дополнительных усилий, то слой приложения останется сцепленным с инфраструктурой. Однако, я считаю, очень часто этого вполне достаточно. А решение расцепить слой приложения и инфраструктуру должно быть обоснованным требованиями конкретного приложения, а не способом реализации по умолчанию.
Заключение
"Program to interface" - хороший совет, за которым скрывается огромный опыт банды четырёх. Однако, если интерпретировать его буквально, то следование ему повысит сложность и стоимость поддержки кодовой базы, ничего не дав взамен. Кроме того, этот совет наиболее актуален при разработке библиотек, фреймворков и платформ с динамической загрузкой кода (плагинами).
При разработке же прикладных программ, намного более простой и поддерживаемый код дают усилия по минимизации протечек абстракций и применение функциональной архитектуры.