Архитектура ориентированная на трансформацию
September 25, 2021
Последние несколько лет я активно топил за чистую архитектуру анкл Боба и даже сделал два с половиной проекта в соответствии с ней:
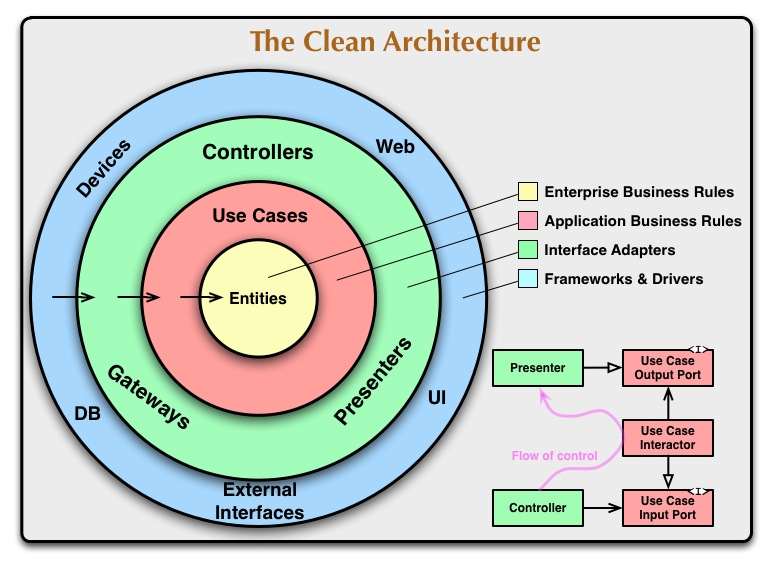
И эти проекты показали, что следование чистой архитектуре генеряет кучу геммороя.
Транзакции в слое интеракторов нельзя обозначать обычной @Transactional - приходится писать кастомный Transactor.
На сущности в домене нельзя навешивать аннотации маппера - я вывернулся отдельным модулем core-data, который зависит от javax.persistance-api грэдловым implementation (который транзитивно не подтягивается в модули, которые от него зависят).
Репозитории нельзя наследовать от Spring Data-вских - приходится определять свои, их наследовать в SpringDataUserRepo и разбираться с адовыми ошибками компиляции при оверрайде генеричных методов.
Это только то, что я сходу вспомнил.
У анкл Боба, помимо нелюбимых мной принципов SOLID, есть и принципы дизайна пакетов, которые мне нравятся намного больше. Один из них - принцип стабильных зависимостей - формулируется просто как "зависимости должны смотреть в направлении стабильности". То есть менее стабильные модули должны зависеть от более стабильных.
Анкл Боб и там продолжает педалировать свою любимую тему инверсии зависимостей, и считает идеально стабильными пакетами те, которые состоят исключительно из интерфейсов, но эта интерпретация мне не нравится:)
Я считаю более стабильными те пакеты, в которых меньше вероятность изменений. Моя версия, конечно, зависит от умения дизайнера гадать на кофейной гуще, но я более-менее научился, так что пусть будет так:)
Так вот, а теперь положа руку на сердце: на что вы больше тратите время - на поддержку изменений в требованиях или на изменение инфраструктурного кода по внешним причинам (всё работает медленно и вы решили переехать с реляционной БД на нереляционную)? По моему опыту на реализацию изменений в требованиях уходит 20-40% времени, а на реализацию изменеий в требованиях к инфраструктуре - 1-5%.
Так кто от кого должен зависеть? Выходит, что домен о инфраструктуры. И так получается даже по Мартиновской интерпретации принципа стабильных зависимостей, если взять типовой бэк на Яве и какой-нибудь спринг или хибер:
Вдумчивый и въедливый читатель скажет: "Погоди-ка, изменения в требования - это как правило логика приложения, а домен - это логика предприятия". На что я отвечу: далеко не все пишут системы автоматизации бюрократизированных корпораций. У многих продукт - делается прямо сейчас и выживаемость продукта зависит от его адаптации к рынку, который продакт вот прямо сейчас пытается понять.
Но на самом деле, эта придирка даже к лучшему и вынудит меня капнуть ещё глубже. В структурный дизайн Ларри Константина из 75-ого года прошлого века:
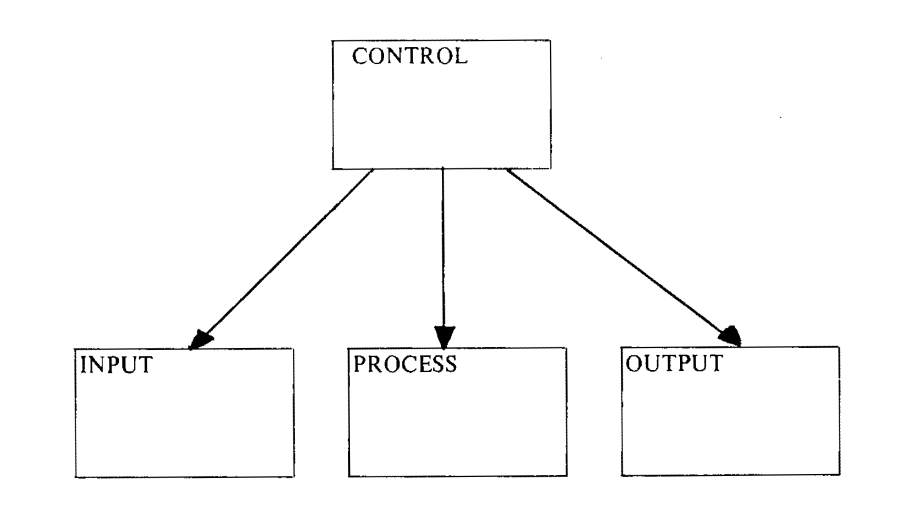
И это самое раннее пока что известное мне свидетельство подхода функциональное ядро + императивная оболочка, в котором я ещё не разочаровался и за который продолжаю топить:
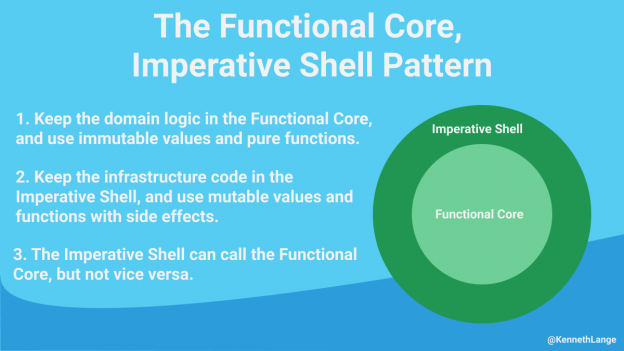
Всё это навело меня на мысль, что я топил не столько за чистую, сколько против слоёной архитектуры.
А начался весь этот пост с этой иллюстрации слоёной архитектуры из Applying UML and Patterns:
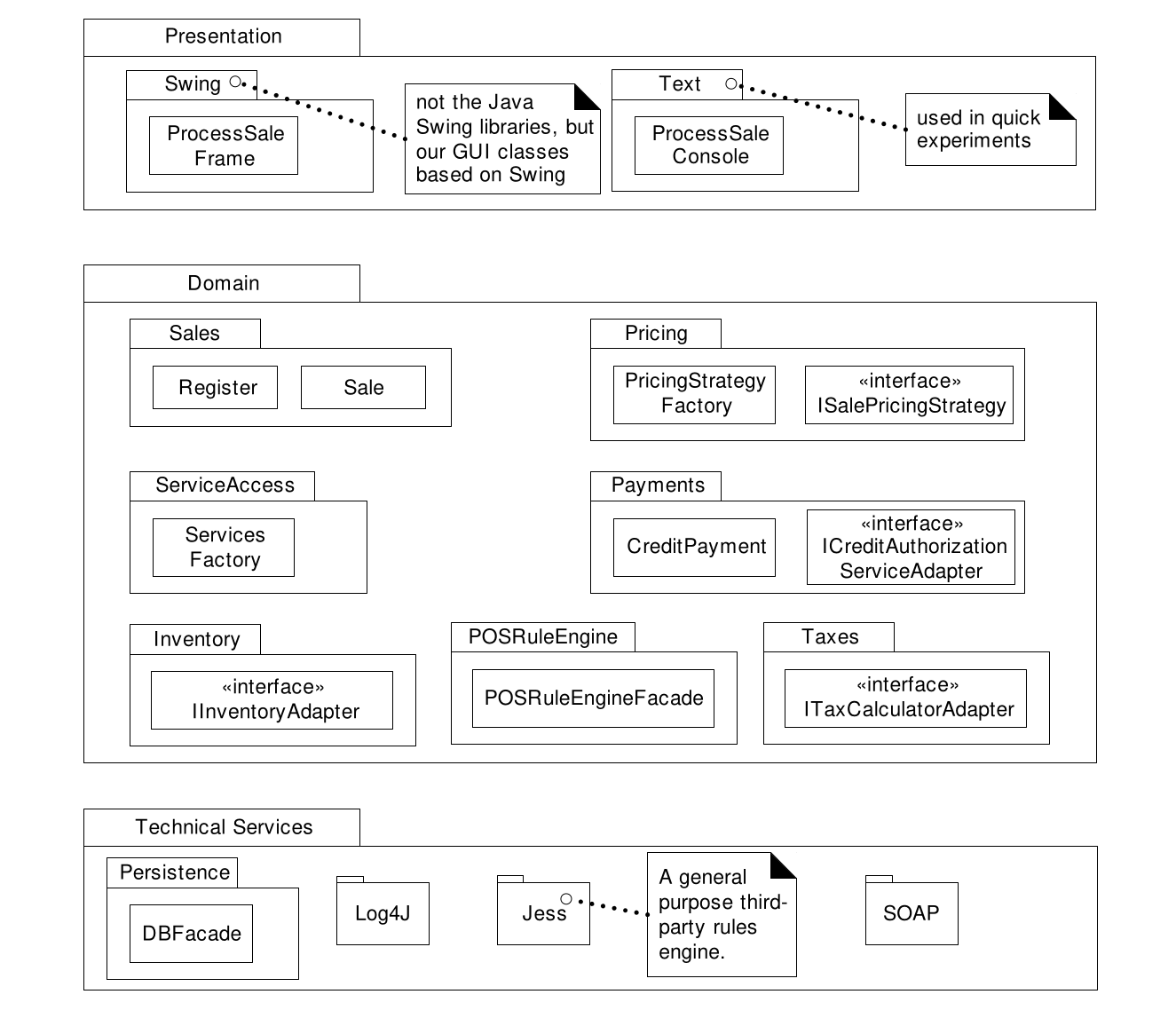
Сравните её с наиболее распространённым пониманием слоёной архитектуры.
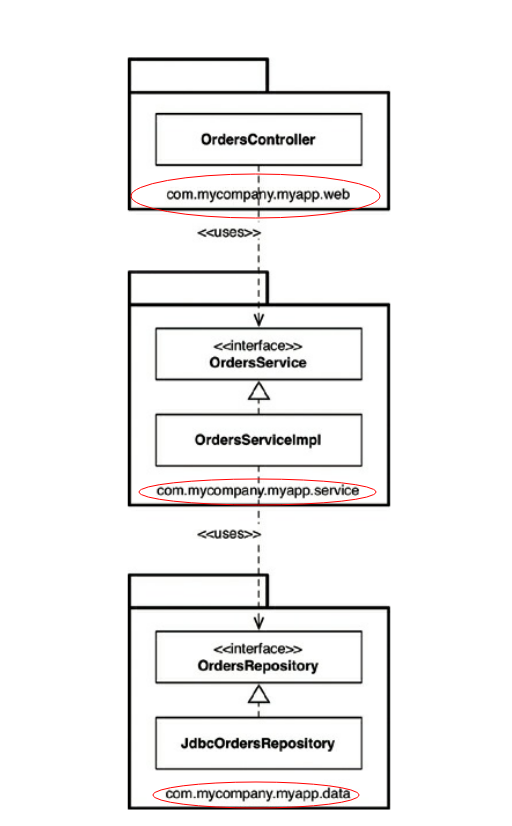
И тут до меня дошло, что я топил даже не против слоёной архитектуры, а против отказа от архитектуры как таковой под видом пакетирования кода по техническим аспектам реализации.
Если же у домена всё-таки будет архитектура - он будет нарезан на ацикличный граф высоко связных (cohesive) и низко связанных (coupling) модулей - то и чёрт с ним, что часть модулей будет зависеть от инфраструктуры, которая практически никогда не меняется.
Чистую архитектуру, инверсию зависимостей и все прочие идеи Мартина надо тащить туда, где вы ожидаете с высокой вероятностью появления различных вариантов реализаций одного и того же поведения. Например у меня в кубите есть абстрактный Storage потому что я сам планирую реализовать поддержку нескольких различных хранилищ, и хочу дать возможность конечным пользователям реализовать поддержку нужного им хранилища. Вот в этом случае вся эта катавасия с инверсией зависимостей оправдана.
А если вы пишете типовой бэк, у которого одно клиентское приложение (и то веб и деплоится вместе с бэком) и одна интеграция (с БД, на смену которой никогда не дадут ресурсов) и половина операций - это тупо круд, то Keep it Simple Stupid(c).
Но не разбивайте код на модули по аспектам реализации - это не "Simple stupid", это "Just stupid".
И того, чтобы волосы были густыми и шелковистыми, надо:
- При реализации отдельной функции системы следовать шаблону Contoll-Input-Process-Output;
- Controll и Process реализовывать в декларативном/функциональном (в виде чистых фукнций, без ввода-вывода) стиле;
- Всю систему надо разбить на модули образующие ацикличный граф. У вас будет два типа модулей:
- Домен в центре, определяет состояние с которым работает система (репозы агрегатов и клиенты внешних сервисов).
- При реализации домена надо думать и гадать на кофейной гуще на предмет того, какие модули будут реже меняться. И зависимости направлять в их сторону. Например, в предпоследнем проекте, я растащил пользователя и его аутентификационные данные. В итоге модуль пользователя оказался в самом центре домена, а модуль аутентификации/авторизации - на периферии. В результате, способ аутентификации менялся три раза, сейчас поддерживается два способа и скоро надо будет третий поддержать.
- Вокруг домена будет приложение, оно определяет функции, которые система выполняет над доменом (состоянием системы). По сути это сервисы, плюс к ним нужны пришлёпки в виде контроллеров, т.к. зависимость сервисов от ХТТП это чёт прям совсем перебор.
- Там ещё есть серая зона, с доменными правилами и подфункциямии, используемыми основными функциями, но это как-нибудь в дргой раз - мне вставать через четыре часа.

Считайте, что это краткое изложение всей моей книги:) По крайней мере как я её сейчас понимаю.